Lucid: A Non-intrusive, Scalable and Interpretable Scheduler for Deep Learning Training Jobs
本文由南洋理工大学与上海人工智能实验室合作,发表于ASPLOS 2023。
现有的面向深度学习的调度器存在两个方面、五点问题:
- 为了获得更好的系统性能,大多数现有的方法依赖于支持抢占的调度:
- 有些调度器要求用户导入特定的库并修改代码来实现这些机制
- 有些调度器需要修改底层DL框架
- 很多调度器需要适应性地调整batch size和learning rate,影响训练的质量
- 许多调度器在实际部署中也存在较大问题:
- 可扩展性有限
- 决策不透明,难以调整
机会
- 对于大部分情况来说,如果把两个job打包放到一个GPU上执行,互相的影响不大;如果考虑混合精度训练中的AMP,packing对训练速度的影响更小:
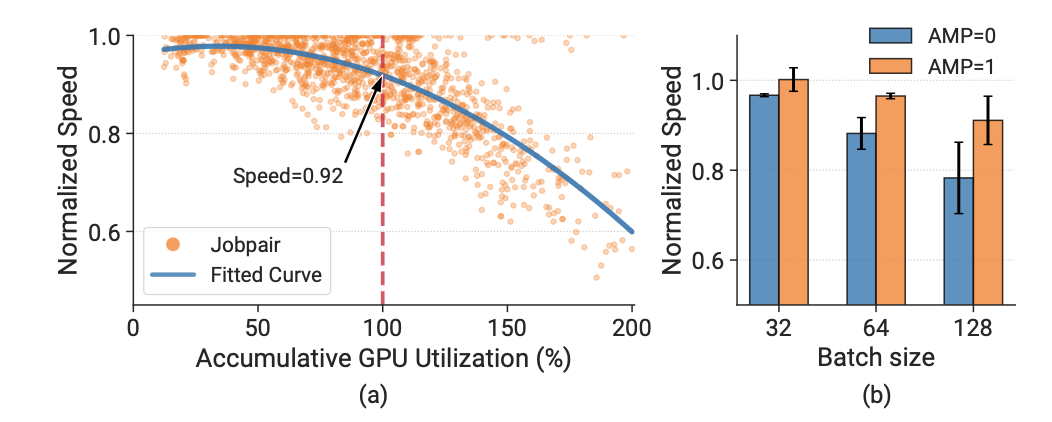 图1:Motivation
图1:Motivation
无需修改DL框架进行packing,训练速度也足够好了。
很多job都是重复提交的。可以通过profiling寻找和其相似的以前提交过的job。
系统设计
Lucid 遵循三个设计原则:
- 非侵入性。整个调度工作流遵循无抢占方式,不需要用户操作和 DL 框架修改。
- 可伸缩性。该系统可以快速获得大量复杂工作负载的调度策略。
- 可解释性。所有的模块都是透明的,可以由集群运营商进行清晰的调整。
此外,Lucid 还提高了资源利用率,并提供了及时的调试反馈。我们未来的工作旨在为更多的调度目标服务,比如公平性和服务水平保证。

图2:System Overview
蓝色块为关键调度器模块,紫色块为用于性能增强和维护的两个系统优化器。工作流:分析作业,记录作业资源使用情况等信息,并把作业分类;绑定器判断是否以及如何打包作业;资源编排器根据概要分析和用户提供的特性,为每个作业分配一个优先级值,并选择要分配的作业。
非侵入的Job Profiler
Affine 作业对 绑定器
资源编排器
可解释模型
系统优化
实验
32GPU的tesebed,商汤的trace。可以降低JCT,提高scalability。
原文作者:Qinghao Hu, Meng Zhang, Peng Sun, Yonggang Wen, Tianwei Zhang
原文链接:https://dl.acm.org/doi/pdf/10.1145/3575693.3575705
Code:https://github.com/S-Lab-System-Group/Lucid
参考链接:[1] 【论文笔记】Lucid论文阅读笔记 https://tweakzx.github.io/p/论文笔记lucid论文阅读笔记/
[2] Lucid总结:一个可扩展和可解释的实用型深度学习任务调度器 https://zhuanlan.zhihu.com/p/612076435