Following the Data, Not the Function: Rethinking Function Orchestration in Serverless Computing
本文是对即将发表于NSDI 2023会议的论文《Following the Data, Not the Function: Rethinking Function Orchestration in Serverless Computing》的解读。服务器无感知(serverless)应用程序通常由函数(function)工作流组成,交换数据需要通过触发多个短期函数以响应事件或更改状态。当前的服务器无感知计算平台通过高级调用依赖关系来协调和触发函数,但忽略了函数之间的底层数据交换。这种设计在编排复杂工作流时既不高效,也不易使用。本文作者认为函数编排应该遵循以数据为中心的方法。本文的Pheromone平台提供了一个数据桶抽象来保存函数生成的中间数据。开发人员可以使用数据触发器原语来控制每个函数的输出何时以及如何传递给工作流中的下一个函数。通过明确数据消耗并允许其触发函数和驱动工作流,可以轻松高效地支持复杂的函数交互。与商业平台和开源平台相比,Phromone将函数交互和数据交换的延迟降低了一个数量级,可扩展到大型工作流,并可轻松实现复杂应用程序。
研究背景
当前的服务器无感知计算平台使用“面向函数的方法”来编排和激活服务器无感知工作流的函数:每个函数被视为一个单独的单元,函数之间的交互在工作流中单独表达。这样的方式存在以下三个缺点:
表达能力有限
当前的函数编排假定数据流与在工作流中调用函数的流相同,并且一个函数会立刻直接调用其他函数,将全部输出传递出去。 这个假设并不适用于很多应用程序。可用性有限
当前的服务器无感知计算平台为函数之间的数据交换提供了各种选项:函数可以通过消息代理或共享存储同步或异步地交换数据,还可以处理来自各种来源的数据,例如嵌套函数调用、消息队列或其他云服务。因此,当前服务器无感知计算平台缺乏一种在函数之间交换数据的最佳方法,开发人员为了有效地在函数之间传递数据必须找到自己的方法,这些方法可能是动态的、琐碎的,这导致服务器无感知应用程序的开发和部署变得非常复杂。适用性有限
以数据为中心的函数编排
本文作者注意到中间数据(即函数返回的结果)通常是短暂的且不可变的:在数据生成后会等待被消耗,然后过时。由于中间数据一旦生成就不会更新,因此使用它们来触发函数不会导致一致性问题。作者将数据消耗显式化,并使其能够触发目标函数;开发人员可以指定何时以及如何将中间数据传递给目标函数,并触发它们的激活,从而驱动整个工作流的执行。
为了方便以数据为中心的函数编排,作者设计了一个数据桶(bucket)抽象和一个触发器原语列表。 图1概述了如何触发函数。 服务器无感知应用程序创建一个或多个保存中间数据的数据桶。 开发人员可以用触发器配置每个桶,这些触发器指定数据何时以及如何调用目标函数并由它们使用。 执行工作流时,源函数直接将其结果发送到指定的桶。 每个桶检查配置的触发条件是否满足(例如,所需的数据已经完成并准备好被消耗)。 如果是,则桶自动触发目标函数并将所需数据传递给它们。 这个过程发生在所有桶中, 这些桶共同驱动整个工作流的执行。

作者为桶设计了各种触发原语,以指定如何触发函数。 函数间的交互模式大致可分为直接触发器原语、条件触发原语、动态触发器原语三类,如表1所示。
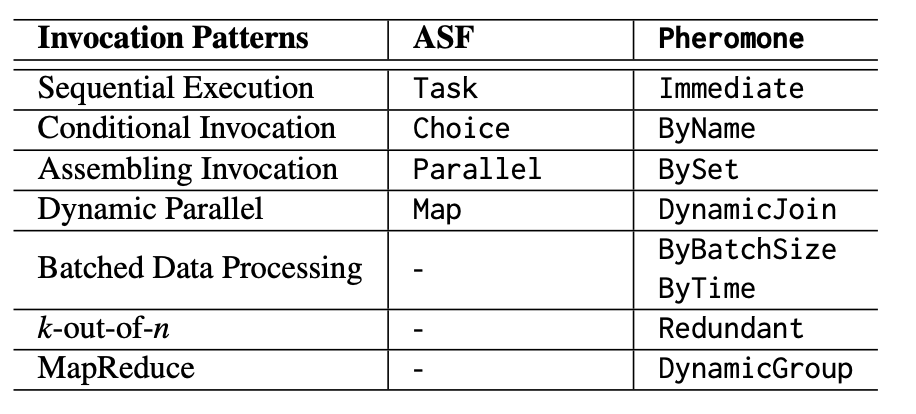
Pheromone平台目前支持用C++编写的函数,并能够支持更多语言。 Pheromone还提供了一个Python客户端,开发人员可以通过该客户端编写函数交互。

Pheromone系统设计
图2展示了Pheromone的系统架构。 每个工作节点接收来自本地调度器的指令,并运行多个执行器,这些执行器根据需要加载和执行用户函数代码。 工作节点还维护一个共享内存对象存储,该存储保存由函数生成的中间数据。 对象存储提供了一个数据桶接口,通过该接口,函数可以在一个节点内以及与其他节点有效地交换数据。Pheromone还会通过可持续的键值存储同步需要长期保存的数据,当新数据添加到对象存储时,本地调度器检查关联的桶触发器。 如果满足触发条件,本地调度器将在全局协调器的帮助下本地或远程调用目标函数,全局协调器在工作节点以外的单独机器上运行。

本文设计了一个两层的分布式调度方案来将Pheromone扩展到一个大的集群中。 具体地说,外部请求首先到达全局协调器,全局协调器将请求发送到工作节点上的本地调度器。 本地调度器尽可能通过调度使得后续函数在本地执行工作流,从而减少调用延迟。

Pheromone使用节点上的共享内存对象存储来维护数据对象,这样函数就可以通过指针直接访问数据。当源函数通过send_object()将数据对象放入bucket时,就标记它为“就绪”。 桶可以分布在其负责的协调器和多个工作节点上,其中每个工作节点跟踪本地数据状态,而协调器持有全局视图。桶状态同步只需要在负责的协调器和工作节点之间进行,因为不同工作节点的本地状态只跟踪他们的本地对象。
由于中间数据是短暂且不可变的,本文用它们的持久性来换取快速的数据共享和低资源占用。通过节点上的共享内存对象存储,Peromone可以通过将数据对象的指针传递到目标函数,实现本地函数之间的“零复制”数据共享,从而避免了大量的数据复制和序列化开销。
为了有效地将数据传递给远程函数,Pheromone可以在节点之间直接传递数据对象。 一个函数将数据对象的元数据(例如,locator)打包成发送到远程节点的函数请求。远程节点上的目标函数使用这样的元数据直接检索所需的数据对象。与使用远程存储进行跨节点数据共享相比,这种直接数据传输避免了不必要的数据复制,从而减少了网络和存储开销。虽然远程存储方法可以确保更好的数据持久性和一致性,但对于中间数据来说这些是不必要的。
Pheromone支持各种类型的容错。如果执行器宕机或工作节点上的数据对象丢失,Pheromone会重新启动失败的函数以复现丢失的数据并恢复中断的工作流。 如果在指定的超时时间内没有收到预期的输出,桶触发器就会重新执行源函数。
实验验证
本文评估了在没有任何有效负载的情况下函数的延迟。 本文考虑了三种常见的调用模式:顺序执行(例如,两个函数链)、并行调用(扇出)和聚合调用(扇入)。 作者在实验中改变了并行和聚合调用的函数的数量,以控制并行度。 图4显示了在这三种模式下调用的延迟。 每个延迟数据被进一步拆分为外部调用和内部调用的开销。
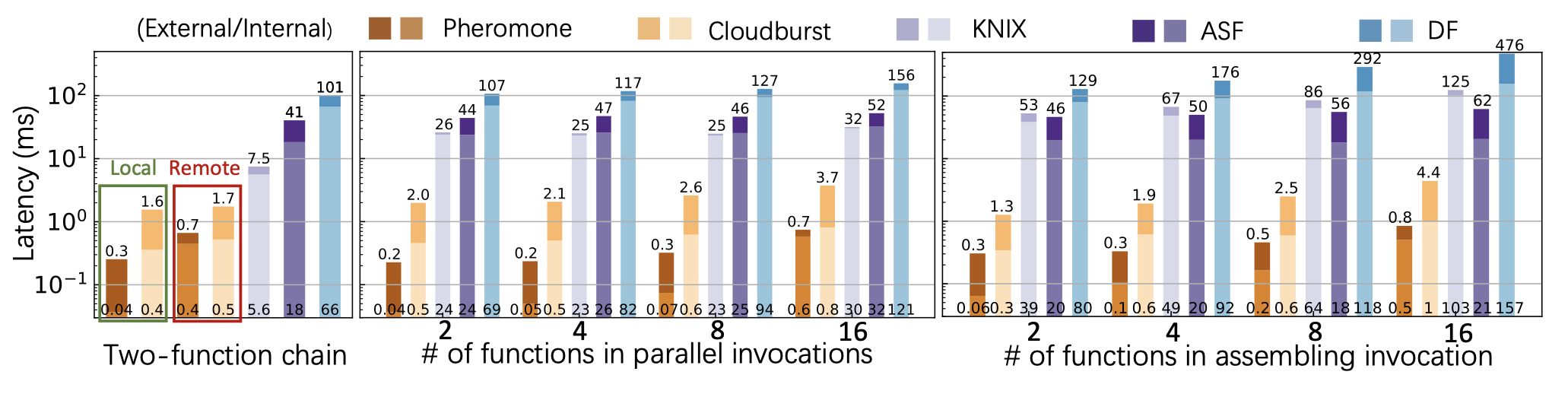
左图比较了在五个平台上测量的两个函数的函数链的调用延迟。 Pheromone明显优于其他方法。 其中Pheromone的基于共享内存的消息传递只带来不到20微秒的开销,将本地调用延迟降低到40微秒,比CloudBurst快10倍。 与其他平台相比,延迟的改善变得更加显著。 当调用远程函数时,Feromone和CloudBurst都需要网络传输,从而导致类似的内部调用延迟。 然而,由于CloudBurst需要在服务请求之前调度整个工作流的功能,CloudBurst对外部调用的开销比Pheromone高,从而导致整体性能更差。
中间和右图分别显示了并行调用和聚合调用下的调用延迟。 本文在每个worker上配置12个执行器,从而在运行16个函数时强制远程调用。 结果显示,Pheromone在各种情况下都具有最佳性能,并且在所有情况下只产生亚毫秒级的延迟,即使对于跨节点函数调用也是如此。
原文作者:Minchen Yu, Tingjia Cao, Wei Wang, Ruichuan Chen
原文链接:https://arxiv.org/pdf/2109.13492.pdf