Elastic Resource Sharing for Distributed Deep Learning
这篇文章是KAIST的박경수教授指导的工作,发表于NSDI 2021。作者提到,资源的分配和调度策略对于深度学习训练任务(DLT jobs)的平均任务完成时间(JCT, job complete time)有很大的影响。“最短剩余时间优先”等传统的方法在这方面表现得很差(只盲目地优先短的任务太粗粒度了)。这篇文章发现,对于加速DLT任务的执行来说,:(1)资源效率(resource efficiency,即一块GPU的边际吞吐量,如果一个任务使用的GPU数量变多,相应资源效率会下降)比段任务优先更重要;(2)如果对已有任务采用贪心算法会使得JCT增加。根据这些发现,作者提出了AFS来平衡资源效率和短任务的优先,与此同时限制资源分配中的不现实的优化。作者同时建立了一个透明化处理对模型的并行训练,并高效处理共享资源调整的DLT系统CoDDL。
研究背景和动机
问题与挑战
减少集群中任务的JCT很重要。本文的目标:最小化JCT。
现有工作的局限性:
- Tiresias和Themis等调度器可以提高“结束早的”任务的优先级,却忽略了长时间运行的DL任务
- Tiresias和Gandiva等调度器的算法不支持弹性资源分配(elastic training)
本文提出了一种可以减小集群中平均JCT的动态调度方法,该方法中每个DL任务使用的GPU数量会不断调整。
挑战:
算法层面:需要同时考虑到任务时长和resource efficiency -> 设计新的调度算法
系统层面:现有auto-scaling和GPU间通信的API的overhead太大 -> 实现了CoDDL这个系统来减小overhead
调度算法
本文的弹性资源共享希望可以平衡短任务和高效任务之间的优先权。寻找最优分配策略看起来是一个NP完全问题。此外,未来作业的到达在调度时是未知的,可能会严重影响之前的资源重新分配决策。本文首先通过对简化问题的严格分析并观察。
算法概述
问题的定义
- 每个DLT job $j_k$在任一时刻被提交到一个有$M$块GPU的集群
- 集群中的每个job都采用bulk-synchronous-parallel (BSP)模式训练
- 一共有$n$个job,对于每个job集群需要两次重新分配:开始和结束。每次重新分配都是一个event。
- 找到n维向量$R_u$={$r_{1,u}$, $r_{2,u}$, …,$r_{n,u}$}, $1 ≤ u ≤ 2n$,$r_{k,u}$是在第$u$个event之后分配给$j_k$的GPU数量
方法
- 找到最优的R_u需要对还没有到达的future job的知识(详见附录A)。
- 因此本文希望找到一个可以减少平均JCT的启发式策略。
- 不断地使用贪心策略依赖于这样一个假设:已完成任务释放的资源只会被已有任务使用,这在一个新的任务到来时会显得“过于乐观”。
- 这说明,调度器假设集群中所有正在执行的任务都只会不断地增加它所使用的资源数量,而不会减少;这和事实严重不符。
AFS假设:假设集群中每一个任务在未来的资源使用会保持不变,然后在此基础上找到最优的方案。这很简单,而且接近实际的集群环境(大多数情况下资源竞争的程度不会有特别大的变化)。
其中,AFS在为任务调整使用的GPU数量的时候是strong sclaing,即global batch size不变。
通过分析两个任务的情况得到的启示
两个任务,一块GPU
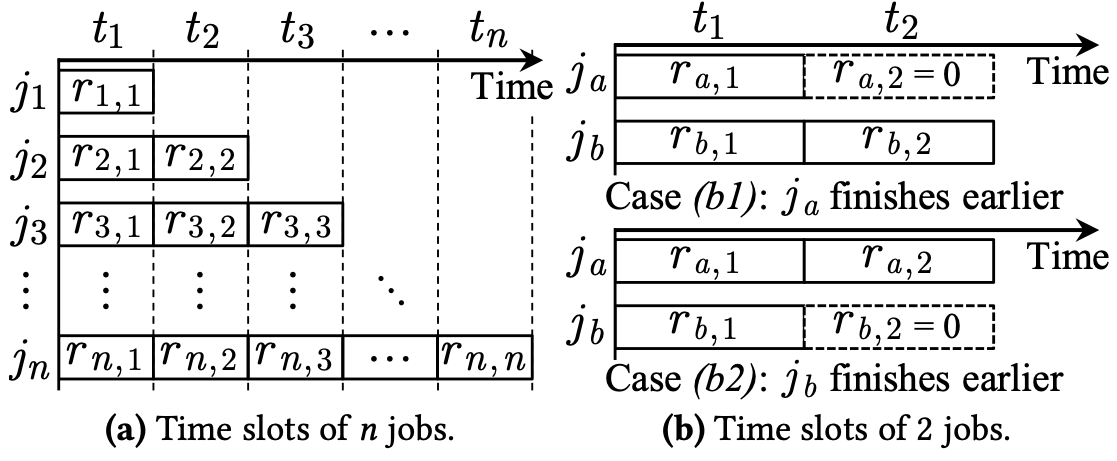
此时,若任务a更短,则($r_a,1$, r_a,2, r_b,a, r_b,2) = (1, 0, 0, 1);否则,(r_a,1, r_a,2, r_b,a, r_b,2) = (0, 1, 1, 0)
两个任务,M块GPU (M > 1),待分配GPU为1块
假设任务a比b先完成。假设已经有M-1块GPU分配给了两个任务如何决定剩下的一块GPU要分给谁?
用$w_k$来表示任务k所需要的训练iteration数量,$p_k,u$表示任务k分配有$r_k,u$块GPU时的吞吐率。可以用这些符号表示出t1和t2:
$$
t_1 = \frac{w_a} {p_{a, 1}} , t_2 = \frac{w_b - p_{b, 1}t_1}{p_{b, 2}}
$$
将这一块GPU分配给不同的任务,最终的任务完成时间不同。同样可以用这些符号表达出不同情况下的任务结束时间。需要找出可以使得完成时间最早的GPU分配方案。
两个任务,M块GPU (M > 1),待分配GPU多于1块
反复执行以上步骤,直到分配完成
处理后续的任务
通过正文和附录里对多种情况的分析,说明(1)在未来有新的任务加入时,可能会使得之前最优的资源分配不再是最优选择;(2)如果新加入的任务使得资源竞争更加激烈,把更多的GPU分配给所需时间长但是更高效的任务是更好的选择。
Apathetic Future Share
AFS假设:任何当前已有的任务在未来得到的资源分配都和现在的相同,即使这个过程中有的任务结束并释放了资源。基于这个假设,之前用于计算GPU分配的公式变得非常简单:
$$
\frac{p_{b,1}’-p_{b,1}} {p_{b,1}’} > \frac{p_{a,1}’-p_{a,1}} {p_{a,1}’}
$$
其中$p_{k,u}’$表示比$p_{k,u}$多用一块GPU的吞吐率。
AFS假设在一些情况下并不是最优的,但是作者认为这些情况在实际集群中不常见。
多任务的AFS算法
从2个任务扩展到n个任务
AFS-L:n个任务量量比较优先级,对M块GPU一次分配,时间复杂度为O(M·n)。
AFS-L算法分为两个阶段:(1)假设所有任务都在单GPU上运行,如果M比任务的数量少,算法停止,否则(2)通过衡量每个任务所需时长和资源效率,决定如何分配剩下的GPU。

处理任务时长未知的情况
AFS-L算法要求已知任务所需时长。作者把AFS-L算法中找出优先级最高的任务的计算方法,修改为衡量之前提到的简化后的公式。如果通过这个公式也找不到更好的方案,最随机分配GPU。修改后的整个算法被称为AFS-P。在AFS-P中,如果任务的数量多于M,则通过记录下来的每个任务历史的资源分配情况,决定哪些任务可以优先得到GPU。
CoDDL系统
CoDDL系统在文中的介绍并不详细,该系统基于团队在OSDI‘18的一篇poster:Efficient Resource Sharing for Distributed Deep Learning。

用户只需提交单机代码,该框架就可以运行数据并行的训练。CoDDL实现了自己的通信栈,在scaling时将无需通信的GPU op与新加入GPU的初始化overlap。
作者没有提通信上的overlap;据说做一次scale out只需4ms。但是无论在本篇论文中还是之前的poster中,都没有介绍overhead为什么可以这么低。
作者声称share shrinking中只需发信号给通信栈然后停掉相应kernel,这是zero cost的,只需4ms。
有许多reconfiguration同时到来的时候,每个worker可以“取消”正在进行初始化的reconfiguration。
CoDDL有自己的容错机制,而且支持job migration。
实验评估
对AFS算法从模拟和实际集群实验两方面进行评估。使用了有16台机器、每台机器4块GTX 1080 GPU的集群进行实验。workload基于微软137天的实际的trace。根据trace计算每个模型训练所需的iteration数,并根据此来进行后面对JCT的模拟。
对算法的评估分为两组:一组的算法中,任务时长已知,另一组的算法中任务时长未知。对于实际集群中的实验,都从平均JCT、最长完工时间、GPU利用率等等多个方面进行了评估。AFS在各个方面的表现和其他的调度算法相比,都合理且优秀。
作者还评估了CoDDL share re-adjustment的效率。没有和其他论文的方法进行比较,而是和没有reconfiguration cancelling的方法,以及既没有op overlap也没有reconfiguration cancelling的方法进行了比较,证明这两方面的优化可以让任务更快结束。
总结
这篇文章的项目开始于2017年,到2021年才发表。AFS可以将集群中任务的平均JCT提升2.2倍至3.1倍。该方法只考虑了数据并行。该算法没有考虑用户对使用的GPU数量有自己的需求,如果用户要求一个任务使用大量的GPU,但是AFS算法认为这样不利于平均JCT,是否就无法满足用户的要求进行gang schedule了呢?另外,本文实验中仅考虑了训练一个模型所需的iteration数,没有考虑在改变了训练所用GPU数量之后,训练了这些iteration后模型的准确率是否达到了标准。
其他问题:不支持模型并行;没有考虑GPU之间的topology。
原文作者:Changho Hwang, Taehyun Kim(共同一作), Sunghyun Kim, Jinwoo Shin, KyoungSoo Park
原文链接:https://www.usenix.org/system/files/nsdi21-hwang.pdf
CoDDL Poster:https://chhwang.github.io/pubs/osdi18_poster_hwang.pdf