
Resources for Machine Learning System
总结机器学习系统领域的学习资源,以及值得关注和阅读的paper,主要涉及分布式深度学习、集群调度等。

每天一个没用的代码小技巧
一些小技巧、小方法的合集。每天一个小技巧,效率翻倍!

DistFlashAtten:面向长上下文大语言模型训练的内存高效的分布式注意力机制
本文介绍了一种名为DistFlashAttn的分布式内存高效注意力机制,它是为了优化长上下文大型语言模型(LLMs)的训练而设计的。文章提出了三种关键技术:token级别的工作负载平衡、交叠的键值通信,以及重计算梯度检查点算法。这些技术使得DistFlashAttn能够在多设备上高效地分发token块,同时保持内存高效注意力的I/O感知优势。

BPipe: 面向大语言模型训练的内存均衡的流水线并行
流水线并行是在GPU集群中训练大型语言模型的关键技术。然而,流水线并行通常会导致内存不平衡问题,某些GPU的内存压力很大,而其他GPU则没有充分利用其内存。这种不平衡会影响训练性能。为了解决这种低效性,BPIPE在流水线并行中实现内存平衡。BPIPE在训练期间在GPU之间传输中间激活值,使所有GPU都能利用相当大小的内存。通过平衡内存利用率,BPIPE消除冗余重新计算或增加微批大小,从而提高GPT-3等大型语言模型的训练效率。

Lucid:一个可扩展、可解释的实用型深度学习作业调度器
现有的深度学习作业调度器存在可扩展性有限、决策过程不透明等等问题。本文引入了一个二维优化的探查器用于高效收集作业度量和及时调试作业反馈,利用惰性包装策略来规避干扰,并根据估计的作业优先级值和共享分数来协调资源,以实现高效的调度。Lucid实现了较好的模型性能维护和系统透明调整。可以减少JCT,并为实际部署提供了明确的系统解释和出色的可扩展性。

Pheromone:服务器无感知计算平台中以数据中为心的函数编排
本文的Pheromone平台提供了一个数据桶抽象来保存函数生成的中间数据。开发人员可以使用数据触发器原语来控制每个函数的输出何时以及如何传递给工作流中的下一个函数。通过明确数据消耗并允许其触发函数和驱动工作流,可以轻松高效地支持复杂的函数交互。与商业平台和开源平台相比,Phromone将函数交互和数据交换的延迟降低了一个数量级,可扩展到大型工作流,并可轻松实现复杂应用程序。

TOPOOPT:面向分布式训练作业的网络拓扑与并行策略协同优化
本文发表于NSDI2023。在本文中,作者对从阿里巴巴 PAI 6000多个GPU的生产MLaaS集群收集的两个月工作负载跟踪进行了表征研究,解释了集群调度面临的挑战,描述了目前的解决方案,并公开了数据集。
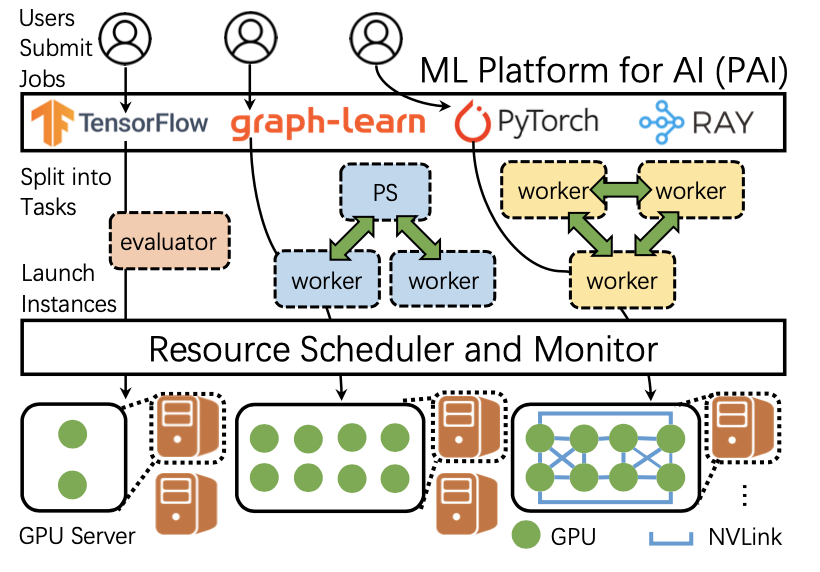
大规模异构GPU集群中的作业负载分析与调度
本文发表于NSDI2022。在本文中,作者对从阿里巴巴 PAI 6000多个GPU的生产MLaaS集群收集的两个月工作负载跟踪进行了表征研究,解释了集群调度面临的挑战,描述了目前的解决方案,并公开了数据集。
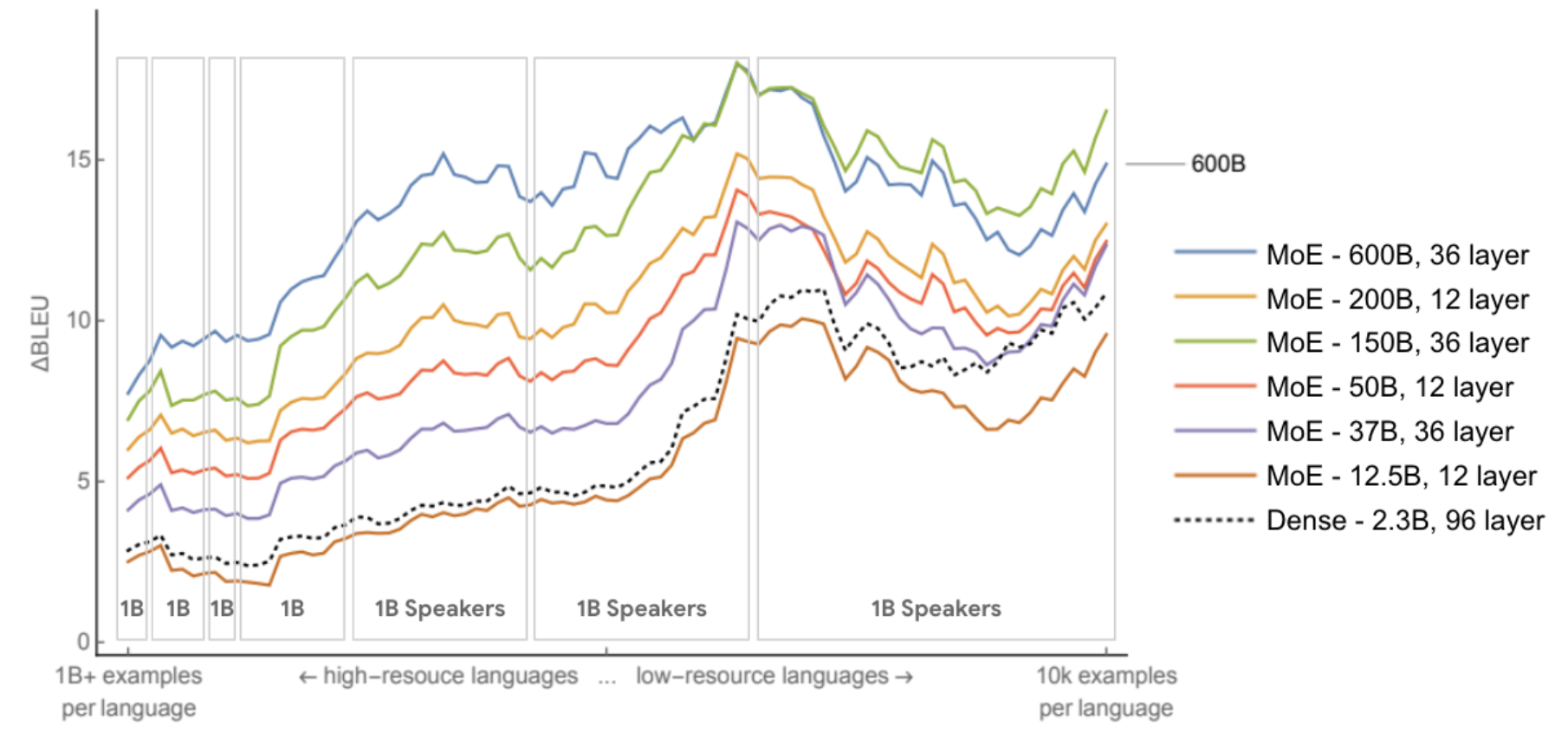
碳排放与大规模神经网络训练
机器学习的计算需求近年来迅速增长,导致成本很高。估算能源成本有助于衡量其对环境的影响并找到更环保的战略。本文计算了几个大型模型的能源使用和碳足迹,并寻找提高能源效率和二氧化碳当量排放(CO2e)的机会。

Blink:面向分布式机器学习的快速、通用的通信原语
本文发表于MLSys 2020。目前用于深度学习的数据集规模越来越大,基于多个 GPU 的数据并行训练(Data-Parallel Training)大大缓解了大规模深度学习模型训练耗时长的问题,但是跨 GPU 的参数同步在大规模训练时产生了较大开销。本文提出了 Blink——一个通过包装生成树动态生成最佳通信原语的集合通信库。在处理硬件生成中的拓扑异质性问题或集群调度程序中的分配问题时,Blink 能够动态生成给定拓扑的最佳通信原语。