MLaaS in the Wild: Workload Analysis and Scheduling in Large-Scale Heterogeneous GPU Clusters
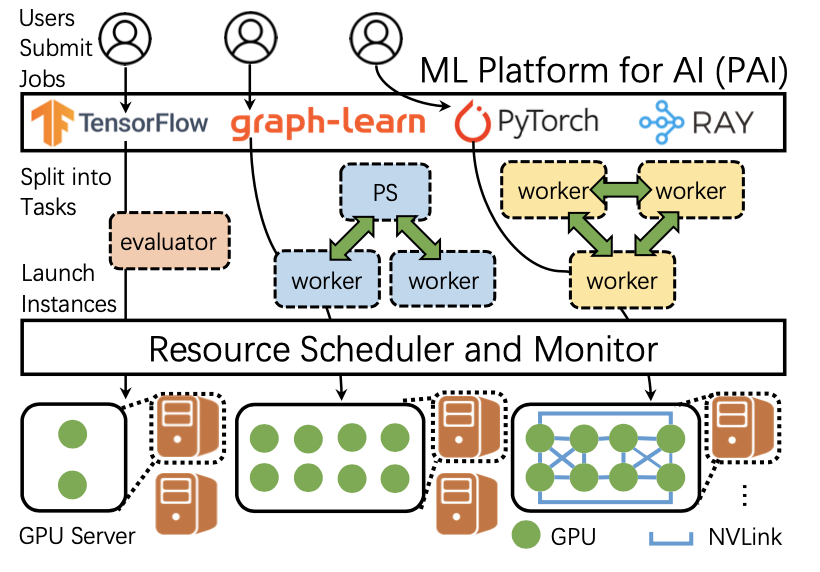
随着机器学习技术的持续进步和海量数据集的使用,科技公司正在部署大型ML-as-a-Service(MLaaS)云,通常带有异构GPU,以提供大量ML应用程序。然而,在异构GPU集群中运行不同的ML工作负载带来了许多挑战。为了适应快速增长的ML工作负载计算需求,阿里云提供了人工智能机器学习平台(PAI),这是一个多功能的MLaaS平台,使开发人员能够高效、灵活、简化地使用ML技术。其架构如图1所示。
在本文中,作者对从阿里巴巴 PAI 6000多个GPU的生产MLaaS集群收集的两个月工作负载跟踪进行了表征研究,解释了集群调度面临的挑战,包括GPU利用率低、排队延迟长、难以调度的任务需要高端GPU、具有苛刻的调度要求、异构机器之间的负载不平衡,以及CPU上的潜在瓶颈。作者描述了目前的解决方案,并呼吁进一步调查仍有待解决的挑战。作者公开了相关数据集。
数据集概览
PAI的数据集中,大多数作业要求多个GPU。数据集包括不同级别(如作业、任务和实例)的工作负载的到达时间、完成时间、资源请求和GPU、CPU、GPU内存和主内存中的使用情况。数据集还提供了机器级信息,包括守护进程代理收集的硬件规格、资源利用率等。
具有以下特点:
严重倾斜的实例分布。PAI跟踪包含超过1300名用户提交的120万个任务的750万个实例。用户运行的任务实例的分布是严重倾斜的。大约77%的任务实例由前5%的用户提交,每个用户运行的实例超过17.5k个,而后50%的用户每个用户运行的实例不到180个。
组调度(gang scheduling)占主流。在所有任务实例中,大约85%的作业要求组调度,其中20%必须在100多个GPU上调度,有些甚至要求超过1000个。加在一起,带有组调度实例的作业占GPU总需求的79%。这类任务的普遍性使得很难实现高利用率。
GPU局部性。除了组调度,作业可能会请求在同一台机器上的多个GPU上运行其所有实例,这一要求称为GPU的局部性。虽然这种要求通常会导致长时间的调度延迟,但它允许在单个节点(例如NVLink和NVSwitch)内使用高速GPU到GPU互连,从而显著加快分布式训练。在PAI中,对某些训练任务实施GPU局部性可以有超过10倍的加速比。
GPU共享。PAI支持GPU共享,允许多个任务实例以低成本时间共享一个GPU。使用此功能,用户可以在(0,1)区间内指定GPU请求,并使用部分GPU运行其任务实例。GPU共享可以节约大量的GPU资源。
在时间维度上,作业提交频率具有日间模式,工作日提交的作业略多于周末,其中除了白天,午夜也是任务提交的高峰时间;实例运行时间的变化范围很大(第90百分位的运行时间为4.5小时,比Philly的25小时短),作业排队的延迟时间分布很不均匀。
在空间维度上,资源请求的分布呈重尾分布(一小部分的实例请求了大量的资源),GPU使用率很低但CPU使用率较高。
GPU机器利用率
计算资源利用率
如图2所示,与内存(包括主存和GPU内存)相比,GPU和CPU的利用率更高。在8-GPU机器(左上角)中,GPU(红色虚线)和CPU(蓝色实线)的平均P90利用率分别达到82%和77%。在2-GPU机器中(右上角),P90 GPU的利用率仍然很高(平均77%),而P90 CPU的利用率在平均值上下降到42%,这是因为CPU与GPU的比率很大(每个GPU配有32或48个CPU)。在这两种类型的机器中,主存和GPU内存的P90利用率几乎一直低于60%,这说明数据集中的作业的内存密集度较低。
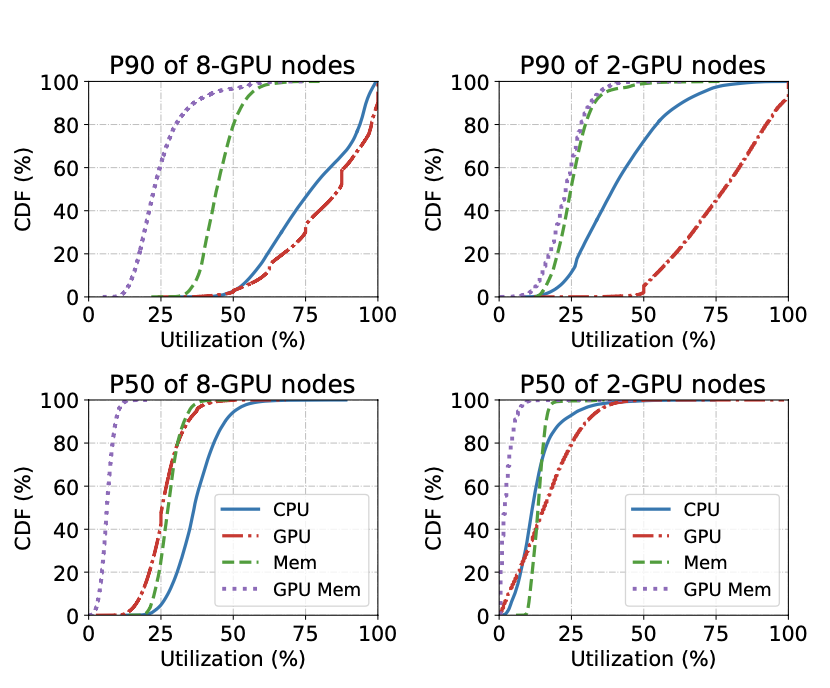
与其他资源相比,在GPU上测量的利用率变化更大。如图2所示,P90 GPU利用率的分布范围很广,在40%到100%之间变化;GPU上的尾部和中值利用率之间的差异也比其他资源上的差异更大。这种巨大的差异是由于在ML工作负载中发现的突发性GPU使用模式。PAI使用的调度器中packing的优先级高于负载平衡也是到这支个现象的原因。
网络与I/O利用率
网络:P100(或Misc)、T4和V100机器中P95网络输入速率分别为带宽的54%、48%和34%。
I/O:I/O等待上的CPU时间比usr比内核模式下的CPU时间小三个数量级,这说明CPU主要忙于处理数据,而不是等待I/O完成。
集群管理的机遇
GPU共享:GPU独享导致GPU利用率很低。为了避免这一问题,PAI支持GPU共享,且GPU共享在及群众补货导致激烈的资源竞争。
重复性任务的可预测执行时间:已知任务执行时间是作出更好调度结果的关键。现有调度器根据训练进度(例如,操作次数、损失曲线和目标精度)和任务速度来预测执行时间。获取此类信息需要特定的框架支持(例如TensorFlow和PyTorch),这在实际集群中并不总是可能的,因为用户可能运行各种标准或版本的框架,而且他们提交的任务可能不会执行迭代训练)。然而,作者发现大多数任务都是重复性的:大约65%的任务至少重复运行5次。作者通过任务定期运行、平均实例运行时间稳定的特征来预测人物运行时间。经过实验评估,PAI使用的预测方法的准确率对于做出调度决定来说是足够的。
集群管理的挑战
挑战包括:机器规格和实例请求之间不匹配、老旧GPU机器中的任务过多、高端机器中负载不均衡、CPU成为瓶颈等
原文作者:Qizhen Weng, Wencong Xiao, Yinghao Yu, Wei Wang, Cheng Wang, Jian He, Yong Li, Liping Zhang, Wei Lin, Yu Ding
原文链接:https://qzweng.github.io/files/2022NSDI-MLaaS-Weng.pdf
公开数据集:https://github.com/alibaba/clusterdata