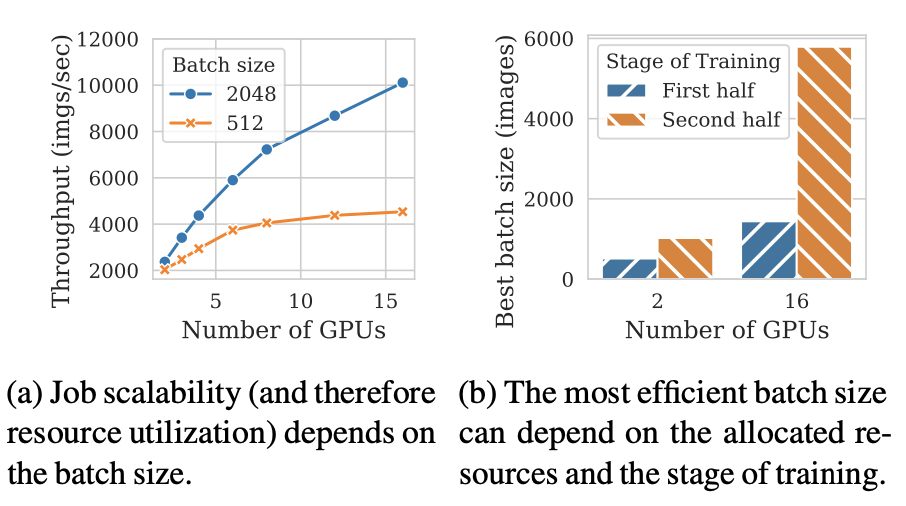
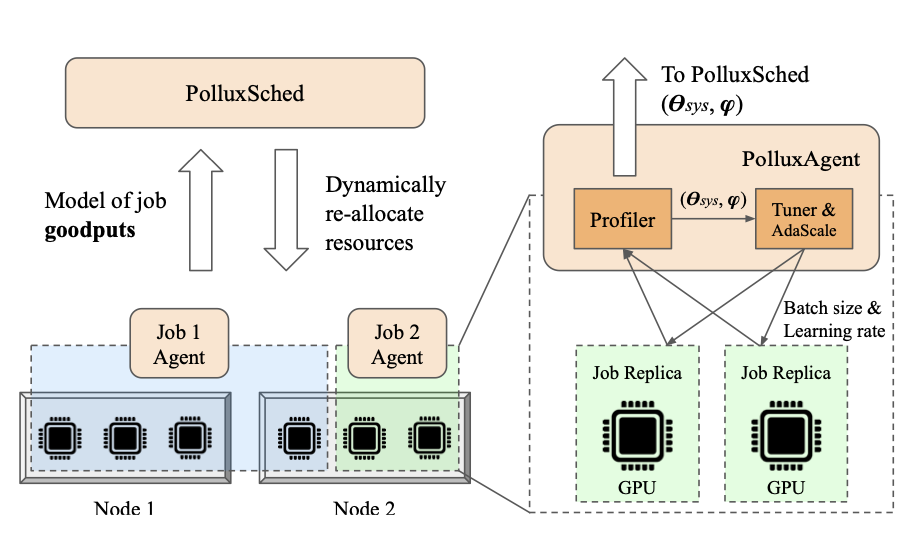
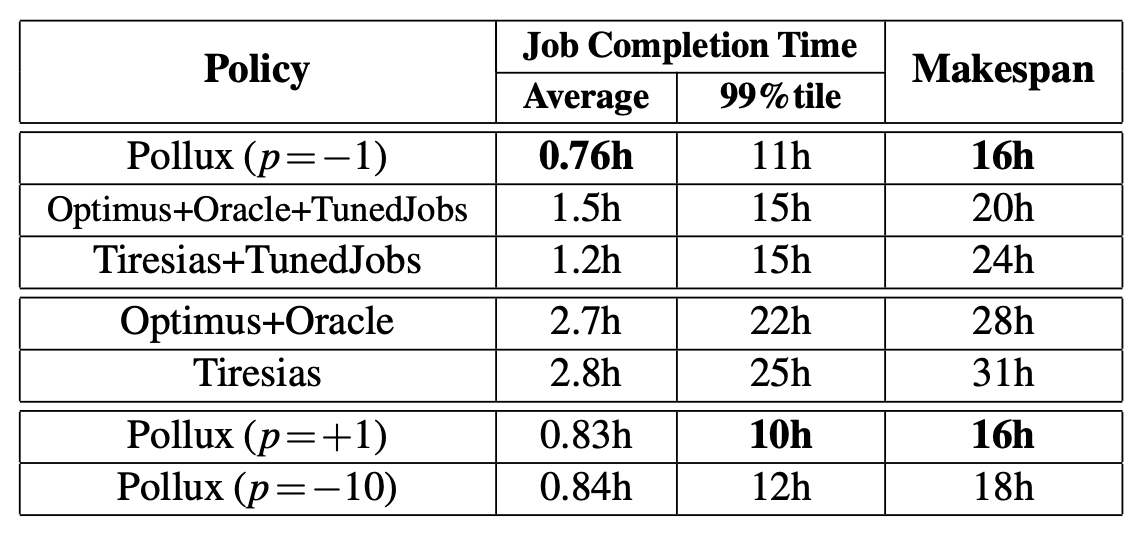
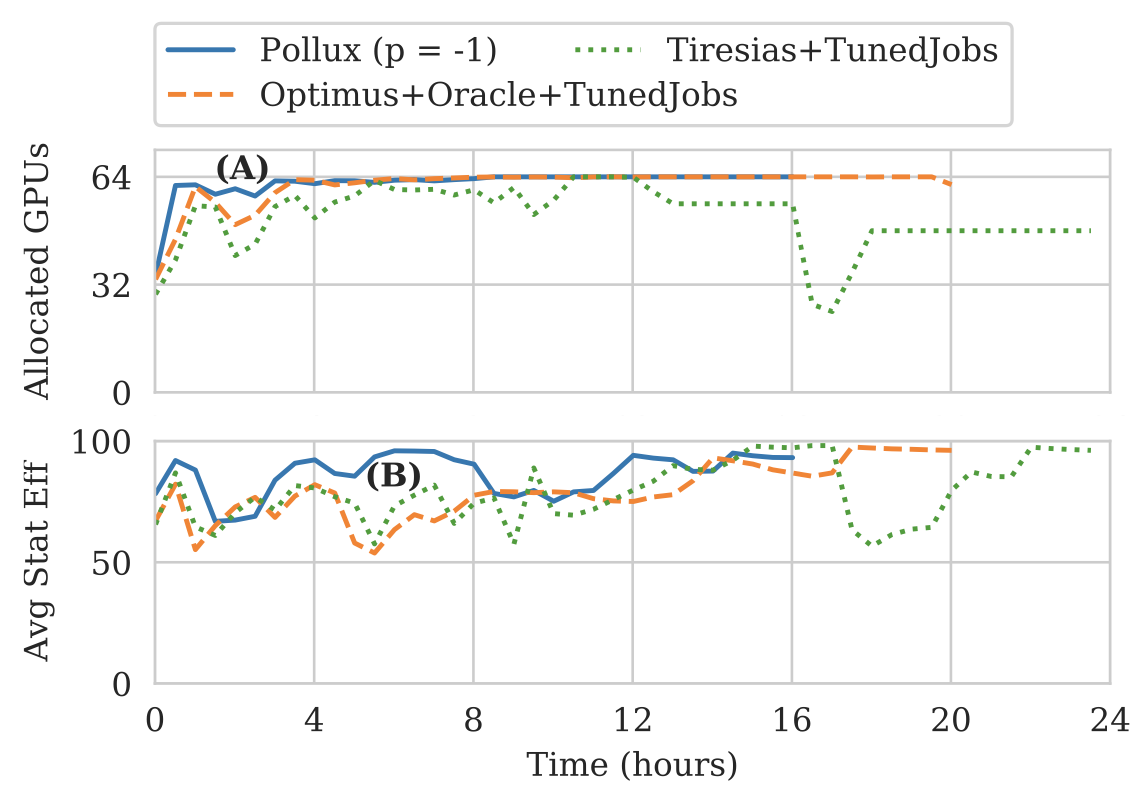
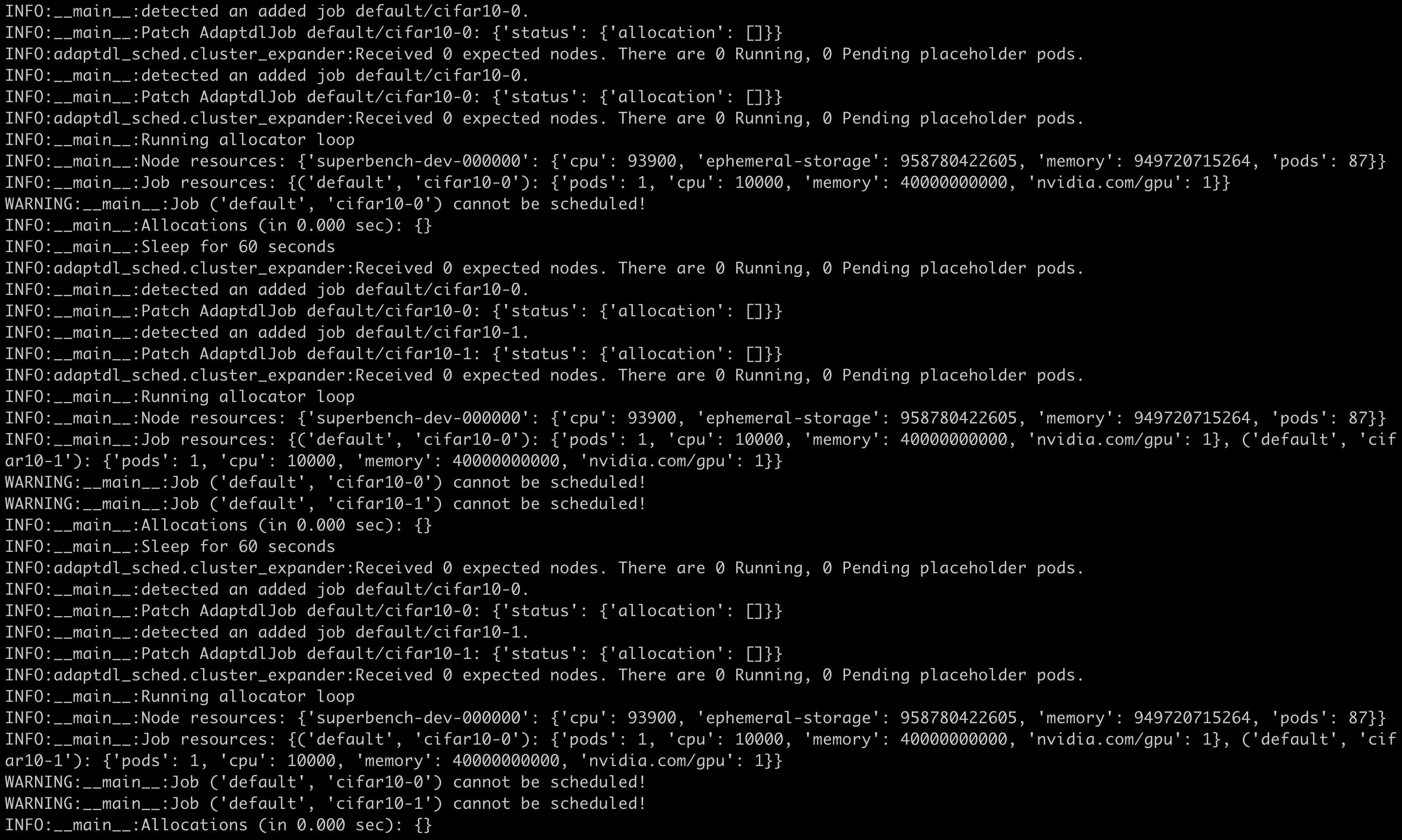
$ kubectl describe pod copy-7pc4z Warning FailedScheduling 115s default-scheduler 0/1 nodes are available: 1 pod has unbound immediate PersistentVolumeClaims. $ kubectl get pvc # the status of the PVC is pending $ kubectl describe pvc pollux Normal Provisioning 3m35s (x27 over 92m) rook-ceph.cephfs.csi.ceph.com_csi-cephfsplugin-provisioner-64d4468bbf-rwrfl_9d4dda0e-3e39-47e5-a5b5-b66b886b22d8 External provisioner is provisioning volume for claim "default/pollux" Normal ExternalProvisioning 3m1s (x361 over 93m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "rook-ceph.cephfs.csi.ceph.com" or manually created by system administrator
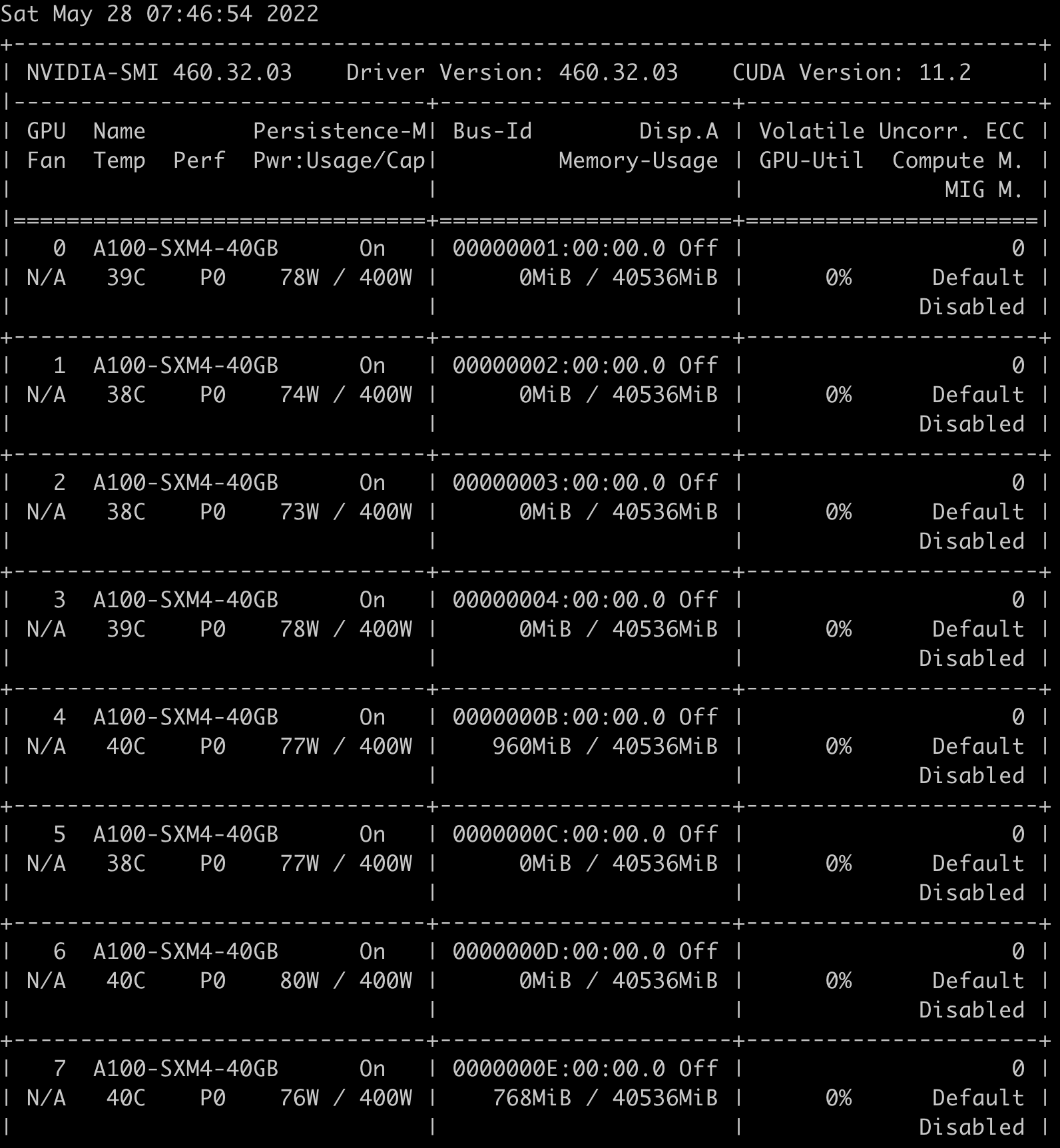
$ kubectl logs nvidia-device-plugin-daemonset-n7f7q -n kube-system 2022/05/27 07:25:44 Loading NVML 2022/05/27 07:25:44 Failed to initialize NVML: could not load NVML library. 2022/05/27 07:25:44 If this is a GPU node, did you set the docker default runtime to `nvidia`? 2022/05/27 07:25:44 You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites 2022/05/27 07:25:44 You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
$ sudo kubeadm init --pod-network-cidr=192.168.0.0/16 --v=5 I0615 07:02:56.149065 39512 initconfiguration.go:115] detected and using CRI socket: /var/run/dockershim.sock I0615 07:02:56.149317 39512 interface.go:431] Looking for default routes with IPv4 addresses I0615 07:02:56.149328 39512 interface.go:436] Default route transits interface "eth0" I0615 07:02:56.149899 39512 interface.go:208] Interface eth0 is up I0615 07:02:56.149966 39512 interface.go:256] Interface "eth0" has 2 addresses :[10.5.0.7/24 fe80::20d:3aff:fe49:1b40/64]. I0615 07:02:56.149982 39512 interface.go:223] Checking addr 10.5.0.7/24. I0615 07:02:56.149987 39512 interface.go:230] IP found 10.5.0.7 I0615 07:02:56.150002 39512 interface.go:262] Found valid IPv4 address 10.5.0.7 for interface "eth0". I0615 07:02:56.150007 39512 interface.go:442] Found active IP 10.5.0.7 I0615 07:02:56.245405 39512 version.go:185] fetching Kubernetes version from URL: https://dl.k8s.io/release/stable-1.txt I0615 07:02:56.587172 39512 version.go:254] remote version is much newer: v1.24.1; falling back to: stable-1.21 I0615 07:02:56.587215 39512 version.go:185] fetching Kubernetes version from URL: https://dl.k8s.io/release/stable-1.21.txt [init] Using Kubernetes version: v1.21.13 [preflight] Running pre-flight checks I0615 07:02:56.929034 39512 checks.go:582] validating Kubernetes and kubeadm version I0615 07:02:56.929090 39512 checks.go:167] validating if the firewall is enabled and active I0615 07:02:56.937774 39512 checks.go:202] validating availability of port 6443 I0615 07:02:56.937886 39512 checks.go:202] validating availability of port 10259 I0615 07:02:56.937905 39512 checks.go:202] validating availability of port 10257 I0615 07:02:56.937926 39512 checks.go:287] validating the existence of file /etc/kubernetes/manifests/kube-apiserver.yaml I0615 07:02:56.937939 39512 checks.go:287] validating the existence of file /etc/kubernetes/manifests/kube-controller-manager.yaml I0615 07:02:56.937949 39512 checks.go:287] validating the existence of file /etc/kubernetes/manifests/kube-scheduler.yaml I0615 07:02:56.937954 39512 checks.go:287] validating the existence of file /etc/kubernetes/manifests/etcd.yaml I0615 07:02:56.937964 39512 checks.go:437] validating if the connectivity type is via proxy or direct I0615 07:02:56.937981 39512 checks.go:476] validating http connectivity to first IP address in the CIDR I0615 07:02:56.937999 39512 checks.go:476] validating http connectivity to first IP address in the CIDR I0615 07:02:56.938010 39512 checks.go:103] validating the container runtime I0615 07:02:57.019188 39512 checks.go:129] validating if the "docker" service is enabled and active [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ I0615 07:02:57.117386 39512 checks.go:336] validating the contents of file /proc/sys/net/bridge/bridge-nf-call-iptables I0615 07:02:57.117456 39512 checks.go:336] validating the contents of file /proc/sys/net/ipv4/ip_forward I0615 07:02:57.117489 39512 checks.go:654] validating whether swap is enabled or not I0615 07:02:57.117530 39512 checks.go:377] validating the presence of executable conntrack I0615 07:02:57.117575 39512 checks.go:377] validating the presence of executable ip I0615 07:02:57.117600 39512 checks.go:377] validating the presence of executable iptables I0615 07:02:57.117625 39512 checks.go:377] validating the presence of executable mount I0615 07:02:57.117650 39512 checks.go:377] validating the presence of executable nsenter I0615 07:02:57.117670 39512 checks.go:377] validating the presence of executable ebtables I0615 07:02:57.117691 39512 checks.go:377] validating the presence of executable ethtool I0615 07:02:57.117712 39512 checks.go:377] validating the presence of executable socat [WARNING FileExisting-socat]: socat not found in system path I0615 07:02:57.117753 39512 checks.go:377] validating the presence of executable tc I0615 07:02:57.117774 39512 checks.go:377] validating the presence of executable touch I0615 07:02:57.117795 39512 checks.go:525] running all checks I0615 07:02:57.209961 39512 checks.go:408] checking whether the given node name is valid and reachable using net.LookupHost I0615 07:02:57.210512 39512 checks.go:623] validating kubelet version I0615 07:02:57.270497 39512 checks.go:129] validating if the "kubelet" service is enabled and active I0615 07:02:57.279877 39512 checks.go:202] validating availability of port 10250 I0615 07:02:57.279947 39512 checks.go:202] validating availability of port 2379 I0615 07:02:57.279966 39512 checks.go:202] validating availability of port 2380 I0615 07:02:57.279985 39512 checks.go:250] validating the existence and emptiness of directory /var/lib/etcd [preflight] Some fatal errors occurred: [ERROR FileExisting-conntrack]: conntrack not found in system path [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` error execution phase preflight k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow.(*Runner).Run.func1 /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow/runner.go:235 k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow.(*Runner).visitAll /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow/runner.go:421 k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow.(*Runner).Run /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/app/cmd/phases/workflow/runner.go:207 k8s.io/kubernetes/cmd/kubeadm/app/cmd.newCmdInit.func1 /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/app/cmd/init.go:152 k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).execute /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:850 k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).ExecuteC /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:958 k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).Execute /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:895 k8s.io/kubernetes/cmd/kubeadm/app.Run /workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/app/kubeadm.go:50 main.main _output/dockerized/go/src/k8s.io/kubernetes/cmd/kubeadm/kubeadm.go:25 runtime.main /usr/local/go/src/runtime/proc.go:225 runtime.goexit /usr/local/go/src/runtime/asm_amd64.s:1371