Elan: Towards Generic and Efficient Elastic Training for Deep Learning
Elasticity可以带来很多好处:(1)有利于集群管理;(2)有许多动态调整batch size,或需要动态资源的优化算法。但是深度学习框架没有很好的支持elastic training,如果在固定数量的资源上运行这些算法,甚至会导致运行效率减慢。因此,需要有一个系统很好地支持elastic training。实现这样一个系统主要由两方面的挑战:(1)如何找到一个既能保证训练效率又能保证convergence的合适的batch size;(2)如何高效进行state replication。
本文由清华大学和商汤合作,获得了ICDCS 2020的最佳论文提名奖。本文仅适用于数据并行。
概览
Elan为每一个任务设置一个application master(AM)。AM负责为调度器提供资源调整服务,并为所有的worker进行资源调整。
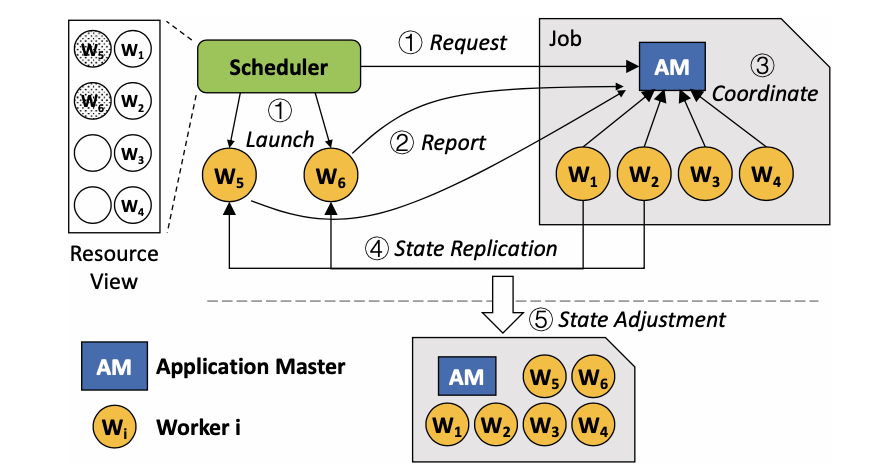
- Request:调度器请求资源调整(scale in、scale out或migration),将请求发给AM并启动新的worker;
- Report:新的worker在启动并完成初始化后,将自身状态告知AM;
- Coordinate:已有的worker和AM进行协作调整;
- State Replication:将训练状态复制给新的worker;
- State Adjustment:例如重新划分数据、重构通信组、调整batch size等。
混合scaling机制
Batch Size
数据并行中scaling out有两种常见策略:strong scaling out(total batch size固定)和weak scaling out(local batch size固定)。前者不能很好地保证训练效率,后者不能保证训练的准确率。本文提出一种将两种方式混合的机制,既能保证效率,也能保证准确率。
对于strong scaling out来说,随着worker数量增大,训练的throughput先上升后下降。对于一个scaling out的请求,Elan首先检查,在调整后的worker数量是否超过throughput最大时的worker数量。如果不超过,则无需调整batch size;否则,将global batch size扩大为两倍,然后再将目标worker数量和新的global batch size下的optimal worker数量进行比较,反复进行这个操作。global batch size扩大的倍数不能超过实际worker数量扩大的倍数。具体算法如下:

Learning Rate
Elan采用progressive linear scaling 规则调整learning rate。根据SGD,learning rate应该随着batch size的增加成比例变化。但是learning rate突然增大会导致模型不converge。因此,Elan在T个iteration的时间里,逐步调整learning rate。
无IO的并发状态复制
训练状态的特点
数据(加载)、模型、通信组和优化器以及一些运行时的信息(例如当前的epoch和iteration数)共同组成数据并行任务里的训练状态。
训练状态有两个特点:(1)训练状态分布在异构的设备中;(2)GPU中的状态比CPU中的状态大得多。
由于这两个特点,状态复制的机制必须满足:(1)很好地管理状态的异构性;(2)高效复制GPU上的状态。
带宽的不同
PCIe连接的GPU之间有三种通信方式:P2P、CPU共享内存 (SHM) 和网络(NET; 在本文中是56Gbps Infiniband)。
集群中GPU间的通信又有四种典型的通信方式: L1:PCIe switches;L2:PCIe host bridge;L3:socket-level link (e.g., QPI);L4:network。对于通信来说,P2P is 只能用于L1,L2和L3可以用SHM,L4只能用NET。
状态复制
- 对于所有的worker建立拓扑树,在复制状态的时候,选择和目标worker最近的worker作为source(P2P > SHM > NET);
- 并发地进行多个replication以充分利用带宽。
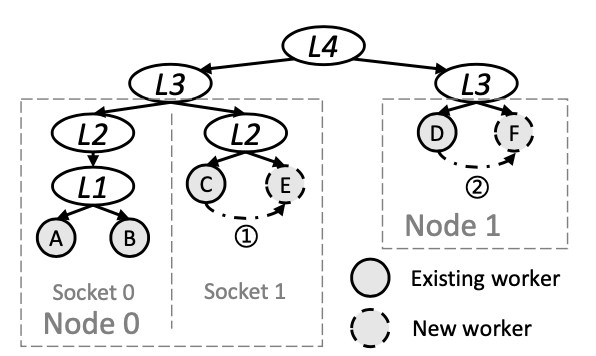
此外,CPU和GPU上的状态复制是同时进行的。
实现
资源调整的过程是shut-down free的,且将启动和初始化新机器的过程和训练overlap起来。

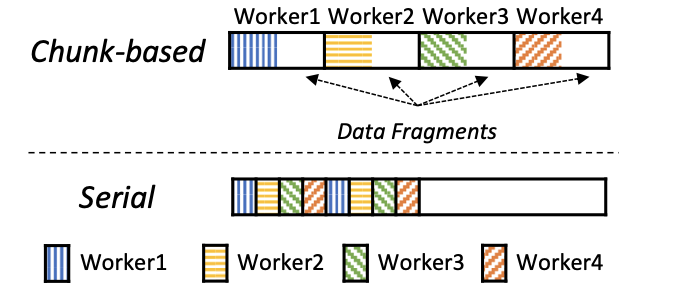
在数据并行中,进行了资源的调整后,需要对数据集进行重新划分。传统的方法是把整个数据集划分为几个部分,剩余的、还未用于训练的数据是碎片化的。Elan采用了一种序列化的方式,这样,剩余的数据就是连续的了,数据集的状态仅仅用一个index来表示未使用的数据的位置就可以了。
实验评估
本文从三个角度对Elan进行评估:资源调整的overhead、动态batch size中获益以及弹性训练调度的获益。
资源调整
使用了8台服务器,各8张卡。
两个baseline:shutdown-restart和Litz(CPU-GPU上下文切换)。
Overhead定义为:如果没有进行资源调整,维持elasticity所浪费的时间(对于Elan来说指的是第四步)。S&R和Elan在这方面overhead是相同的。使用Elan进行资源调整的overhead小于训练总时长的3‰。对于Litz,由于系统的设计不同(?),很难直接比较overhead的大小。作者比较了Litz和Elan的throughput,发现Litz的throughput比Elan小,进而说明Litz的方法中,overhead对训练的影响更大。
另外, 作者比较了S&R和Elan migration,、scaling in和scaling out所用的时间,Elan在各种情况下都优于S&R。
弹性训练
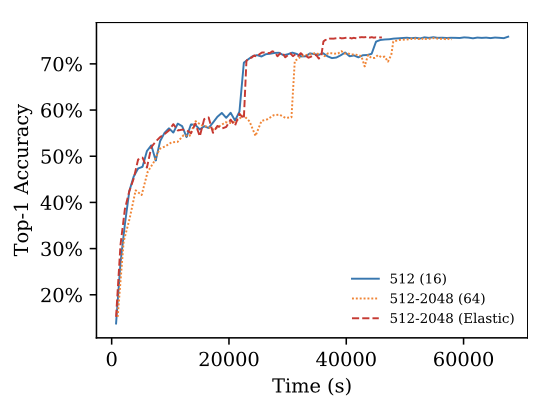
用AdaBatch训练ResNet50。两个baseline:固定batch size和固定worker数量。Elan的训练效率最高且不用想模型converge。
弹性调度
Baseline:FIFO 和 Backfill (BF)。
收集了商汤的trace,并为每个job定义了min_res和max_res。
调度策略:如果有空闲的资源,则为边际增益最大的job添加GPU(类似AFS)。
实验表明,弹性调度可以提高资源利用率,且是必要的。

总结
本文的工作非常全面,实验从多个角度证明了Elastic Training的优点。虽然说调度器理论上不应该任意调整用户定义好的batch size,但是除此以外挑不太出来什么明显的问题,不愧是best paper candidate。
原文作者:Lei Xie, Jidong Zhai, Baodong Wu, Yuanbo Wang, Xingcheng Zhang, Peng Sun, Shengen Yan
原文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9355755&tag=1