HiveD: Sharing a GPU Cluster for Deep Learning with Guarantees
随着深度学习训练需求的不断扩张,很多组织和机构都会选择自建多租户集群来共享昂贵的 GPU 资源。然而现有的GPU集群管理方案因为使用了GPU配额(Quota)机制,可能导致严重的共享异常(Sharing Anomaly)现象:某些租户的深度学习任务甚至比在私有集群中性能更差。为了从根本上解决该问题,微软亚洲研究院和微软(亚洲)互联网工程院、北京大学、香港大学合作提出了一个新的多租户GPU集群管理方案HiveD,通过新的资源抽象和调度框架从而100% 保证共享安全(Sharing Safety),同时不失一般性地和任何任务调度策略兼容。
背景和动机
多租户集群(multi-tenant cluster):HiveD的目标场景是一个集群里有多个tenants(比如公司里不同的团队/部门),每个tenant会贡献一定的资源,这部分贡献的资源就是所谓的私有集群(private cluster)。要保证这些tenants有意愿去共享资源的前提就是,它在共享集群中的性能应该不差于单独拥有一个私有集群时的性能,否则tenant会prefer单独占有这些资源。这个概念在调度领域也叫sharing incentive。
传统的对多租户GPU集群的管理方法:用户申请一定数量的GPU(quota)。为了提高训练速度,用户通常对一个深度学习任务有affinity requirement,即对资源分布的要求(例如,一个需要64张卡的任务需要跑在8台机器各8张卡上)。在多租户集群中没有满足要求的资源的时候,资源管理器可以选择排队等待或用更宽松的affinity requirement。
共享异常:和内存管理中的外部碎片类似。有时候多租户集群中有足够的资源数量,但是这些资源很“碎片化”,无法满足用户的“affinity”的需求,这样的现象被称为“共享异常”。
HiveD:通过一种调度的方法减少全局资源碎片,从而缓解共享异常的现象。但是,减少碎片可能会增大不同任务之间的影响,从而使得任务的训练速度变慢。HiveD不用quota来描述tenant的请求,而是用cell来描述VC(Virtual Cluster)的结构,并给每一个用户分配VC,这样的描述方法可以很好的描述出VC的结构。
系统设计
HiveD采用了两层的架构:第一层是Virtual Private Cluster虚拟私有集群,这一层为用户提供了一个私有集群的“假象”;第二层是实际的集群,从虚拟私有集群(VC)到实际的集群中的设备之间存在着映射关系,如下图所示。
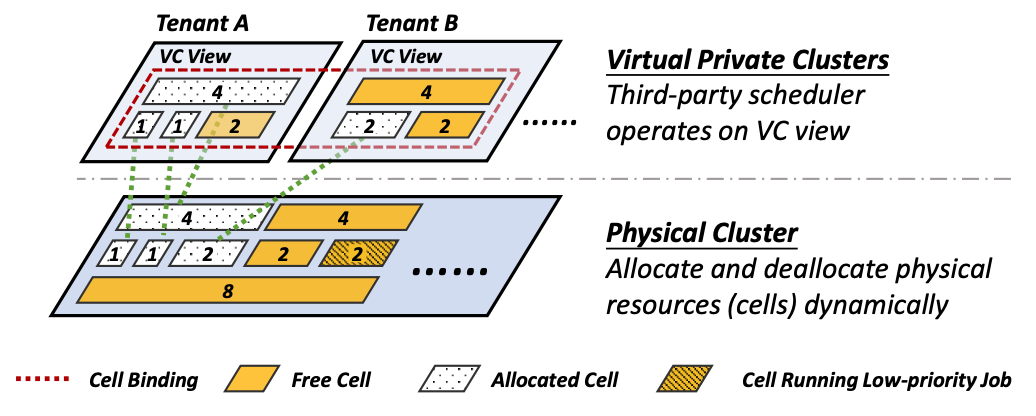
HiveD的这两个layer上各有两点设计/贡献:
VC
- (和quota相比)提出了一种新的对资源抽象的方式——cell,使用这种资源抽象可以同时描述GPU资源的quota和affinity。
- 在VC层面,可以使用现有的深度学习调度器对资源进行调度。
From Virtual to Physical
- 提出了可以保证共享安全的dynamic cell allocation算法。
- 支持low-priority jobs 。
其中,用cell对资源进行抽象以及cell allocation算法可以保证HiveD中的共享安全。在VC层面对调度器的使用可以保证调度效率。对low-priority jobs的支持保证了整个集群中的资源利用率。
带有cell的虚拟私有集群
为了对私有GPU集群进行描述,HiveD定义了一个多层cell结构的层次结构。某一层次上的cell,是具有相应拓扑连接的GPU的对应集合。在每个虚拟私有集群(VC)使用每个级别上的cell数来模拟/描述相应的私有集群。

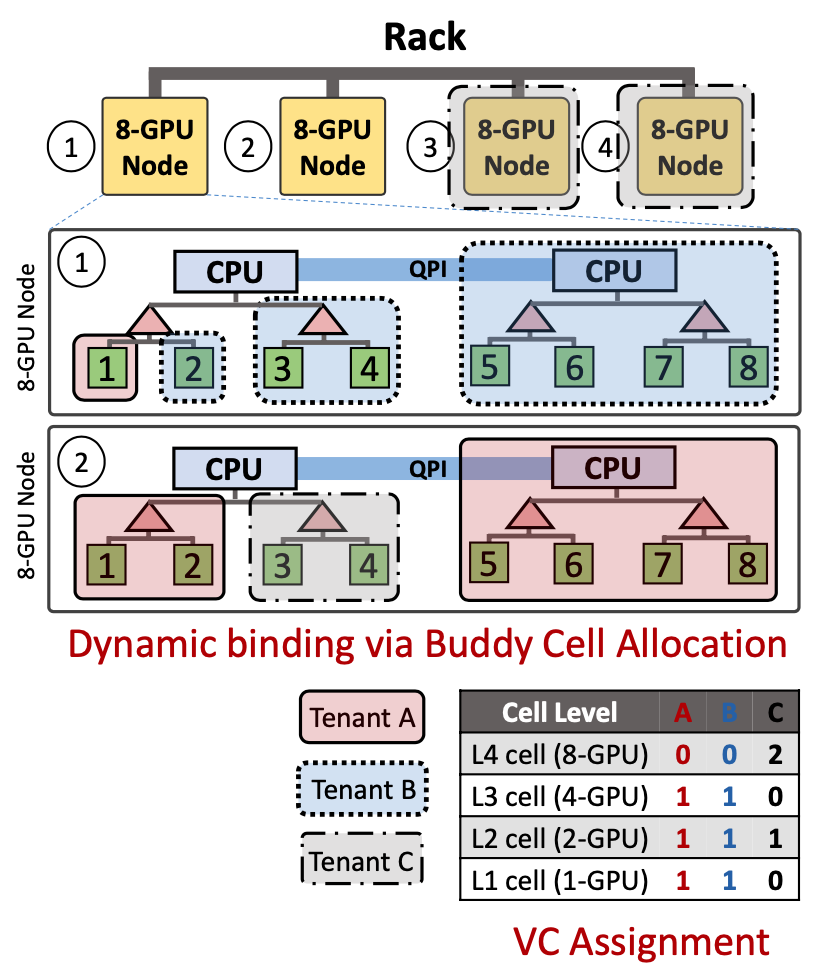
在图3这个例子中,一共有四个层级的cell结构,图中用不同颜色框出了租户A、B和C的一种可能的GPU分配情况,但这不是唯一可行的方案。
在cell层次结构中,k级的cell由一组(k−1)级的cell组成。这些(k−1)级的cell称为伙伴单元(buddy cells);伙伴单元可以合并为下一个更高级别的cell。本文假设cell具有层次一致的可组合性:(i)所有k级cell在满足租户对k级cell的请求方面是等价的,并且(ii)所有k级dell都可以拆分成相同数量的(k−1)级的cell。
Buddy Cell Allocation算法
Buddy Cell Allocation算法其实非常的简单直观:如果需要在VC中分配一个k级cell,算法从k级开始,首先检查是否有可用的k级cell,如果有可用的k级cell则分配一个。否则,算法将逐级上移,去检查(k+1)级或者更高级别的cell,直到有一个可用的l级cell,其中l>k。然后,算法将递归地将一个空闲的l级cell拆分为多个较低级别的cell,直到k级cell可用为止。每次拆分都会在下一个较低级别生成一组buddy cells,这些cell将添加到该较低级别的空闲列表中。
如果有cell被释放的话,该算法会按照与分配cell相反的方式把空闲的cell尽量merge起来,这样保证空闲的cell中有尽量多的更高level的cell。作者通过数学归纳法证明了这一算法可以保证:如果租户原有的VC可以满足一个cell分配,使用该算法在多租户集群中这样的cell分配也一定可以被满足。

该算法可以扩展到支持低优先级的作业(即opportunistic jobs),被低优先级的作业占有的cell可以被高优先级作业抢占。支持这种低优先级的job有助于提高GPU的整体利用率,同时又不损害为VC提供的共享安全保证。
实现
HiveD已经被继承到了基于Kubernetes的开源深度学习训练平台——OpenPAI。HiveD已经在微软已经使用了1年多的时间,用于管理超过1000块异构GPU,为科研和产业workload提供服务。
实验评估
作者首先在96块GPU的集群上进行试验:本文在分别使用了三种state-of-the-art的调度器应用于VC上,进行资源调度。通过比较可以看出,与使用Quota相比,HiveD可以有效消除共享异常;和原始的私有集群相比,任务的queuing delay有明显减小;与此同时,和直接在整个集群上使用调度器相比,任务完成时间(JCT)是差不多一样的。
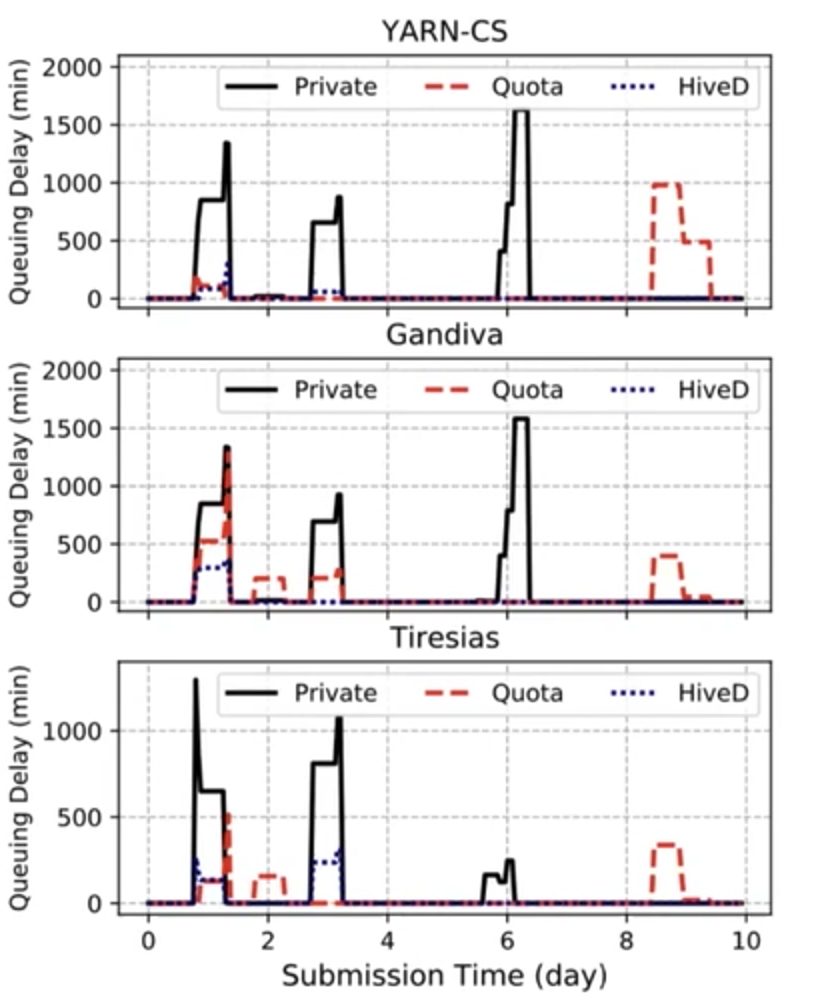
作者还从一个具有2232块GPU、11个租户的集群中手机了2个月的trace,基于trace用96块GPU对这样一个大规模集群上的运行情况进行模拟。在这种情况下,使用HiveD的queuing delay依旧是最短的。

除此以外,作者还对GPU affinity需求和共享安全的权衡等问题进行了的讨论,也通过模拟实验评估了buddy cell allocation算法。
总结
HiveD通过一系列方法应对共享多租户GPU集群的挑战:(i)保障了用户的共享安全,(ii)提出一种新的资源抽象单元cell,用来来模拟虚拟私有集群,(iii)提出了buddy cell allocation算法,该算法被证明能够保证共享安全,并可以扩展到支持低优先级作业,以及(iv)设计一个灵活的体系结构,以结合最新技术共享安全和调度效率的调度程序。
总的来说,HiveD做的事情就是给各个tenant一个正在使用自己私有集群的假象,同时赋予tenants使用自己VC以外的资源来从共享集群中获益的能力。这两方面目标由安全性的定义、cell和VC的抽象以及buddy cell allocation以一个统一的方式实现了。
本文方法仍存在一定的问题。即使使用HiveD,集群中仍然可能会存在碎片。对于HiveD是否能真的像作者提到的那样“完全消除共享异常”,有待讨论。另外cell或许并不能完全准确地描述affinity的需求(不能全面描述GPU之间的拓扑关系)。
Q&A
Q:Tenant是什么?
A:目标的场景就是说一个集群里有多个tenants,比如不同的团队/部门,这在真实场景中都是非常常见的。每个tenant会贡献一定的资源,这部分贡献的资源就是我们所谓的私有集群(private
cluster)。要保证这些tenants有意愿去共享资源的前提就是,它在共享集群中的性能应该不差于单独拥有一个私有集群时的性能,否则tenant会prefer单独占有这些资源。这个概念在调度领域也叫sharing
incentive。Q:当一个VC中的全部job都结束之后,HiveD是否会继续维护这个VC?
A:一般来说,VC和job是无关的。如上面所说,VC本质上就是建模一个tenant原本的私有资源。它跟里面跑什么job没有必然联系,job结束了VC也还在。当然我们支持对VC的reconfiguration,未来可能也会有动态和自动的reconfiguration。Q:HiveD加入了VC这个新抽象以后,VC上的scheduler能知道它能用的GPU之间的拓扑结构之类的信息?
A:每个VC分配的是cell,cell的层次结构里就包含了GPU的topo,GPU本身是leaf cell。Cell是一个tree 的层次结构,所以就算不在一个server里也是有topo的,比如图2 level-5这个cluster里的一个rack cell,里面包含了2个node cell,然后每个node cell下有2个CPU cell,每个CPU cell有两个PCIe switch cell,每个PCIe switch cell下有2个GPU cell,GPU cell是leaf cell。如果config的最高level的cell就是node level,没有上面的rack和cluster了,那几个node cell 之间就没有topo(比如不知道是一个rack下),这个取决于cell的配置里有没有。Cell是tree,所以scheduler里存的也是 tree,除了数量以外层次结构也都在,所以scheduler能知道任意两个cell在 tree 里的位置。
原文作者:Hanyu Zhao, Zhenhua Han, Zhi Yang, Quanlu Zhang, Fan Yang, Lidong Zhou, Mao Yang, Francis C.M. Lau, Yuqi Wang, Yifan Xiong, Bin Wang
原文链接:https://www.usenix.org/system/files/osdi20-zhao_hanyu.pdf
项目代码:https://github.com/microsoft/hivedscheduler
参考文献:[1] OSDI2020——SJTU-IPADS的“云见闻”(二) https://mp.weixin.qq.com/s/GzQSfBYhcU8XccnWV7epKg
[2] OSDI 2020 | 微软亚洲研究院论文一览 https://mp.weixin.qq.com/s/vHeXvAeEPPiTls349yjkAQ
特别感谢原文作者赵汉宇师兄和熊一帆师兄对HiveD设计的讲解!