AntMan: Dynamic Scaling on GPU Clusters for Deep Learning
在大规模GPU集群上高效地调度深度学习作业对作业性能、系统吞吐量和硬件利用率来说至关重要。随着深度学习的工作量变得越来越复杂,GPU集群上的调度变得越来越具有挑战性。本文介绍了一个面向深度学习的、可以实现集群资源弹性伸缩的系统AntMan,它与深度学习框架共同设计集群调度程序,并已在阿里巴巴生产中部署,用于管理数千个GPU上的数万个日常深度学习作业。AntMan利用深度学习训练的独特特性,在深度学习框架中引入了内存和计算的动态缩放机制。评估结果表明,在不影响公平性的前提下,AntMan在多租户集群中提高了42%的GPU内存利用率和34%的计算利用率,为大规模高效利用GPU提供了一种新的途径。
本文由阿里团队发表于 OSDI’21,是一作之一肖文聪博士任职阿里后开展的工作;项目负责人为贾扬清博士(阿里副总裁,pytorch、caffe等框架的主要贡献者)。
研究背景
在过去的几年里,我们见证了GPU上深度学习的巨大成功。大型公司通常会为深度学习工作负载构建多租户GPU集群。在阿里巴巴,我们观察到共享多租户深度学习集群中GPU硬件的利用率很低,同时许多作业等待资源需要很长的时间。深度学习集群的低利用率主要是由两个方面的原因引起的:一方面,训练任务不能充分利用所有的GPU资源;另一方面,深度学习任务的资源通常需要“组调度”(gang-scheduling),这导致许多任务为了获得足够的资源数量而需要等待很长时间。
在共享GPU上打包作业可以提高GPU的利用率,并使同一个集群总体上完成更多的作业。然而,这种方法很少有实际应用,因为这会使不同训练作业之间互相干扰,最终导致训练作业的速度减慢,同时也会造成因内存不足而导致的任务失败。
文章作者提出AntMan,可以在保证作业任务调度公平性以及作业任务训练速度的同时提升集群资源利用率。
动机
文章作者从三个角度研究了生产集群中的资源使用情况:硬件、集群调度和作业行为。
• 正在使用中的GPU的利用率低。 通过对集群中GPU利用率的分析,作者发现只有20%的GPU运行的应用程序消耗了超过一半的GPU内存。就计算单元的使用而言,只有10%的GPU达到80%以上的利用率。这一统计数据表明GPU内存和计算单元没有得到充分利用,从而浪费了昂贵的硬件资源。
• 组调度中GPU资源空闲等待时间长。 为了利用海量数据训练深度学习,分布式多GPU训练是必不可少的。多GPU训练作业需要群调度,这意味着除非所有需要的GPU同时可用,否则作业不会开始训练。然而,在集群中,GPU资源很难同时得到满足。作业需要的资源越多,在空闲等待模式下由于部分资源预留而浪费的GPU周期就越多,集群持有空闲资源所需的成本就越高。
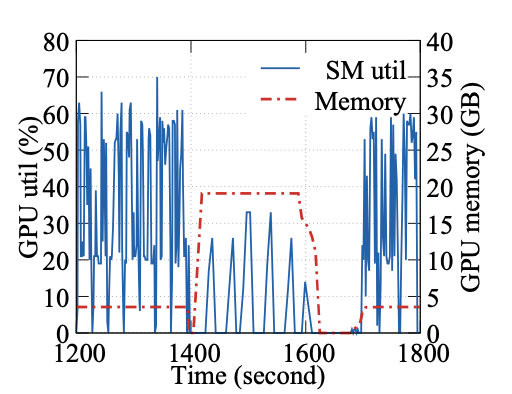
• 训练任务的动态资源需求。 作者发现深度学习训练作业在其生命周期中通常不能充分利用GPU资源。图1显示了在训练ESPnet模型时一段10分钟(1200∼1800秒)的记录。在训练阶段,ESPnet消耗3.6GB的GPU内存,动态GPU Streaming Multiprocessor利用率高达70%。在1400秒时开始evaluation阶段,主要在进行GPU上的解码(大约1400∼1600秒)和CPU上的合成(大约1600∼1700秒),其中解码阶段需要高达19GB的GPU内存。之后继续进行模型训练。这种作业内动态资源需求在生产深度学习pipeline中很常见,因此很难预测训练任务所需资源的数量。这种动态的资源需求与深度学习任务中的固定资源配置以及长时间运行时间相冲突。如果根据峰值使用情况以分配足够的资源会使得昂贵的硬件未得到充分利用。如果没有足够的资源,工作效率可能会受到限制,从而延迟作业完成时间。
与此同时,作者发现了深度学习作业的两个特性:首先,只有一小部分内存用于存储深度学习模型,大部分所使用的内存在每一个mini batch中不断被分配和释放。另外,深度学习训练周期也很短,有80%的任务在600毫秒内就可以完成一个mini batch。根据这两个特性,设计了在共享GPU上调度深度学习任务的方法。
方法设计
深度学习框架中的动态弹性伸缩
动态伸缩机制包括GPU内存和计算单元两个方面的细粒度动态控制。
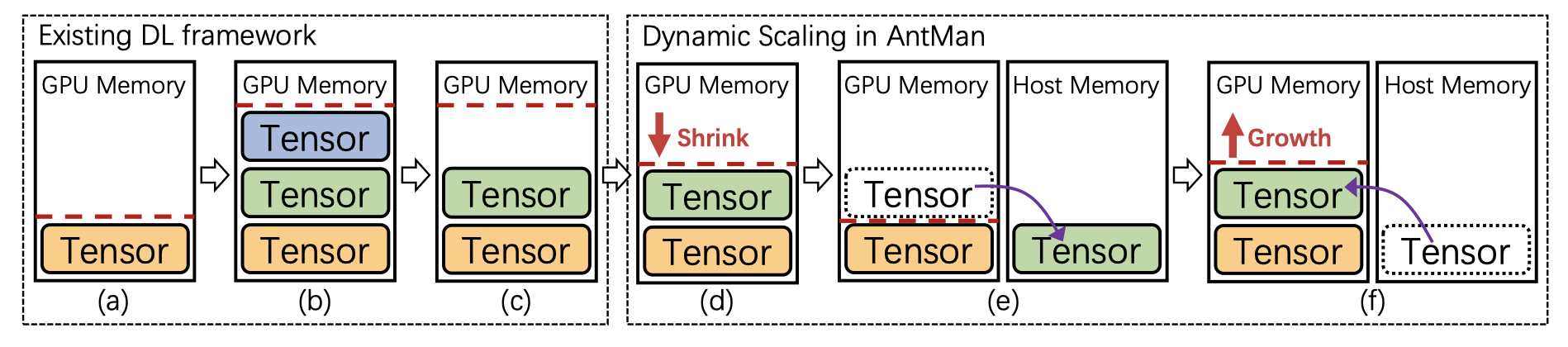
图2说明了现有深度学习框架中的内存管理以及与AntMan的区别。现有深度学习框架中,缓存的GPU内存大小(红色虚线)的总大小随着深度框架中创建的张量而增加(图2a∼b)。一般来说,有些张量只在深度学习训练的某些阶段使用(例如,数据预处理、评估),在其他情况下这些张量是不被需要的。但是,这部分缓存的GPU内存没有释放(图2c)。在这种情况下,分布式缓存框架的性能得到了优化,从而丧失了内存的性能。
AntMan扩展GPU内存上限。它会主动检测已用内存,以收缩缓存内存,从而内省地调整GPU内存使用量,使之适合。这是通过在处理mini batch时监控应用程序性能和内存需求来实现的(图2d)。AntMan尽可能在GPU设备上分配张量,但是,如果GPU内存仍然不足,则可以在GPU之外使用主存分配张量(图2e)。有了这样的通用内存支持,作业甚至可以继续处理低于其实际GPU内存需求的进程。当GPU内存的上限增加时,张量可以自动分配回GPU(图2f)。
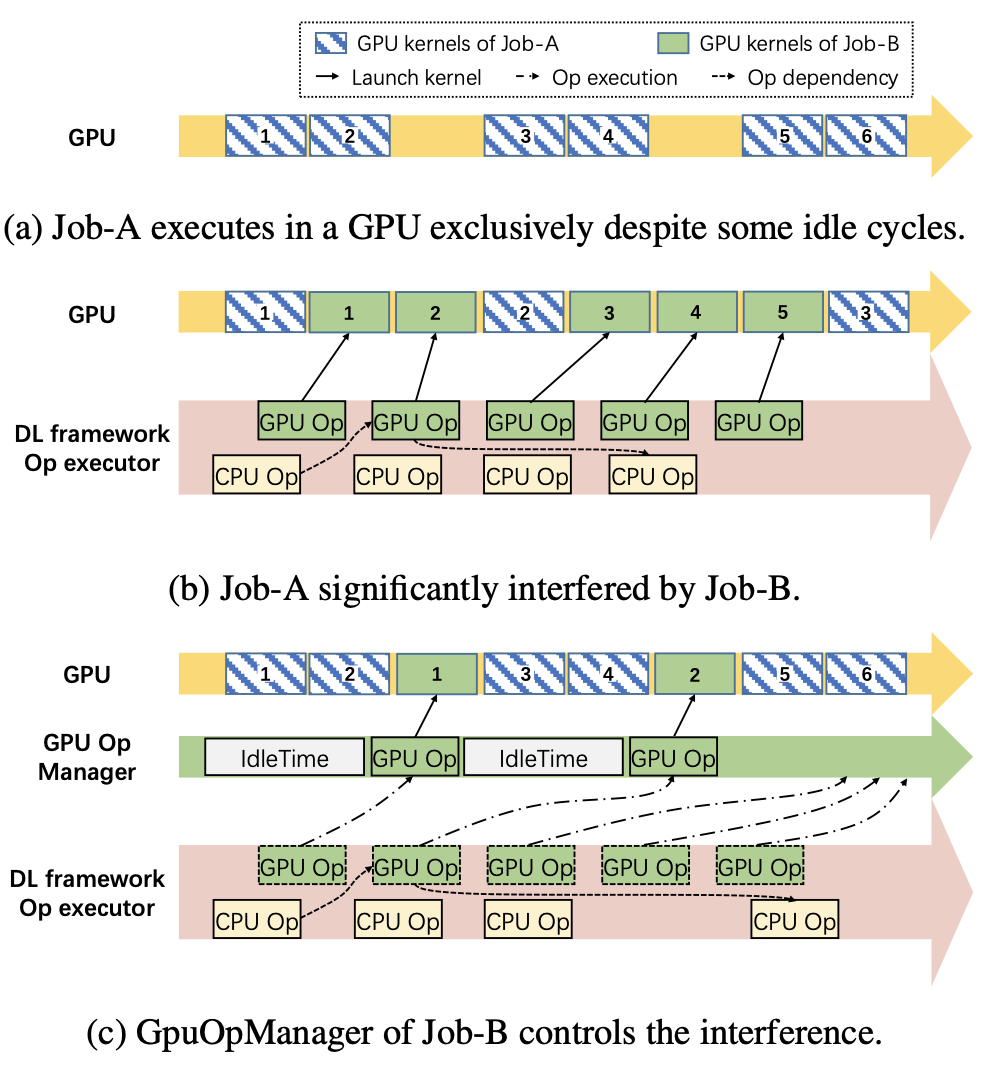
动态计算单元管理是AntMan提出的一种控制深度学习训练作业GPU利用率的机制。通常情况下,如果把两个不同的训练任务打包在同一块GPU上,这两个训练任务会互相影响,导致训练速度变慢(图3a~b)。在AntMan中,GPU op的执行由一个新引入的模块GpuOpManager来控制。当一个GPU op准备好执行时,它会被添加到GpuOpManager中,而不是直接启动。GpuOpManager持续分析GPU op的执行时间,并在启动GPU op之前简单地分配空闲时隙(图3c)。这样就达到了控制两个任务训练快慢的目的。
协同调度器
如图4所示,AntMan采用了层级结构,其中全局调度器负责作业调度。每个工作服务器都包含一个本地协调器,该协调器负责通过考虑来自深度学习框架的统计信息,使用动态资源伸缩的原语来管理作业的执行。

在AntMan中,作业被全局调度器分为resource-guarantee jobs和opportunistic jobs两种类型,并应用不同的调度策略。默认情况下,全局调度器将估计作业的排队时间,有长队列延迟的作业将作为opportunistic job自动执行。用户也可以为了避免排队时间过长自行将训练任务设置为opportunistic job。对于guarantee jobs来说,AntMan会保证他们有足够的资源。而对于opportunistic jobs来说,AntMan会尽量快地为其分配资源,但不保证所分配的资源是足够的。
而本地调度器从三个方面保证调度的公平性。第一,每块GPU上只能有一个resource-guarantee job,本地调度器会通过控制opportunistic jobs所使用的资源来尽量保证resource-guarantee jobs的资源使用。第二,本地调度器通过深度学习框架记录训练任务的一些日志,如果发现resource-guarantee job 增加了GPU内存的需求,即把一些张量存到主存里了,就会减少opportunistic job所使用的内存。Resource-guarantee job对GPU计算资源使用增加的情况也是类似的。第三,对于不同种类的深度学习模型,增加内存对他们performance的提升效果是不同的。AntMan优先把资源给那些只要有一点内存增加就有比较显著performance提升的训练任务。
实验评估
作者从三个方面对ANtMan进行了评估:首先评估了AntMan的动态弹性伸缩机制,以说明动态弹性伸缩机制在深度学习作业中是必要的且高效的;然后将AntMan和其他的集群调度器进行对比;最后通过AntMan在阿里巴巴集群中部署应用前后的集群使用情况说明AntMan可以提升GPU集群中训练任务的效率和表现。
作者将AntMan和其他几种在同一块GPU上训练两个不同任务的训练策略进行比较(表1),使用AntMan时不会因为内存不足而导致训练任务失败,且作业完成时间最短,验证了AntMan内存动态弹性伸缩的必要性。

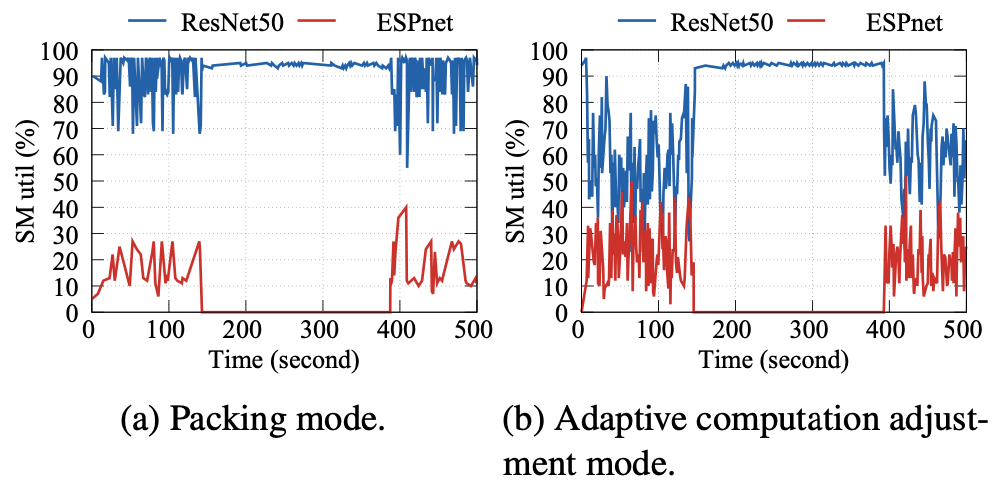
如图5所示,作者将ResNet50训练任务和ESPnet训练任务放在同一块GPU上执行,并比较了在“打包模式”和动态计算资源调整模式下GPU计算资源利用率的表现。实验结果表明,AntMan的策略可以提高opportunistic job对GPU计算资源的利用,与opportunistic job单独使用一块GPU训练时相比,AntMan的方法可以做到在ResNet50模型训练任务维持57%的效率的情况下,几乎不会造成对opportunistic job训练效率的影响。
作者比较了在阿里巴巴集群上使用AntMan之前和之后训练任务的排队时长和集群中硬件的使用情况。比较结果表明,AntMan为这个集群中的深度学习训练任务提供了高达17.1%的额外GPU资源。硬件统计显示,AntMan的GPU内存使用率平均提高了42%,GPU利用率平均提高了34%。由于集群吞吐量的提高,作业请求延迟平均减少了2.05倍,尾部延迟显著减少了一个数量级以上。使用了AntMan之后,99%的任务在与其他任务协同工作时不受影响。
总结
文章提出了AntMan,一个部署在阿里巴巴GPU集群中的深度学习基础设施。AntMan可以在运行时对单个深度学习作业的GPU资源进行灵活的细粒度控制,并设计集群调度器和深度学习框架进行协同作业管理,使得GPU能够尽可能充分利用GPU,同时避免对其他作业任务的干扰。AntMan在不影响调度公平性的前提下,将阿里巴巴GPU集群的GPU内存利用率和计算单元利用率分别提高了42%和34%。
原文作者:Wencong Xiao, Shiru Ren(共同一作), Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, Yangqing Jia
原文链接:https://www.usenix.org/system/files/osdi20-xiao.pdf
项目代码:https://github.com/alibaba/GPU-scheduler-for-deep-learning