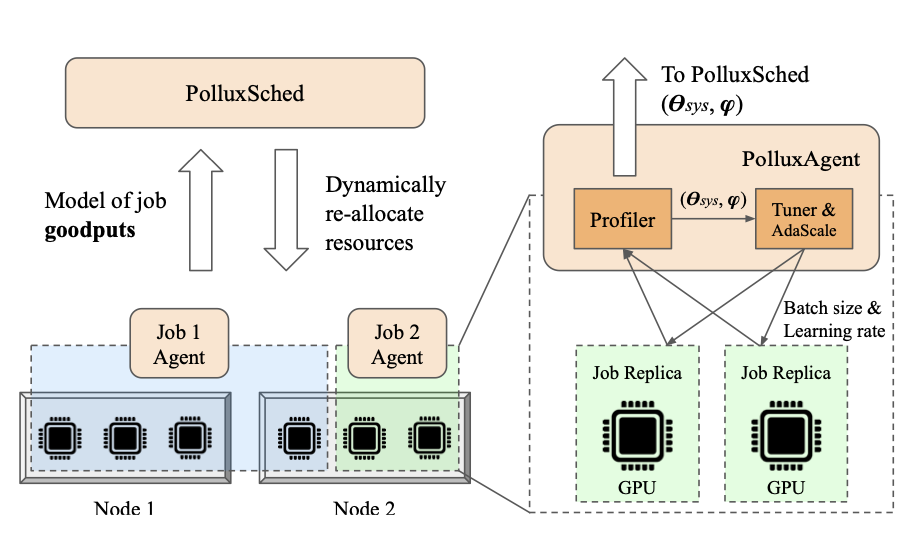
Pollux:面向深度学习有效吞吐量优化的协同适应集群调度
本文是OSDI'21会议的best paper,由Petuum磐腾科技提出的GPU集群调度方法,可以在训练时动态调整资源数量,为深度学习训练的不同阶段找到合适的batch size,从而使得训练效率和训练的准确率都能够得到保障。

AFS:分布式深度学习中的弹性资源共享
在这篇文章中,作者度量并分析了分布式训练的网络表现。作者预期,度量结果会证实通信是阻碍分布式训练达到linear scale-out效果的原因。但是,作者发现实际上网络带宽利用率很低,如果网络带宽可以被充分利用,分布式训练的scaling factor可以接近于1。
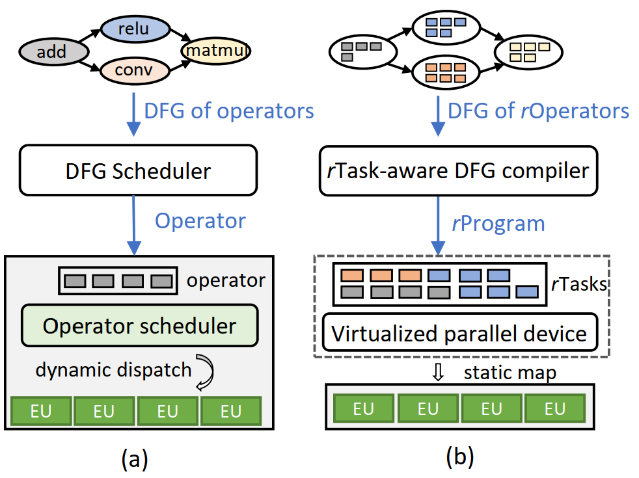
Rammer:如何通过全局视角编译深度学习计算
Rammer是一个可以成倍甚至几十倍地提升深度学习inference计算速度的编译框架。
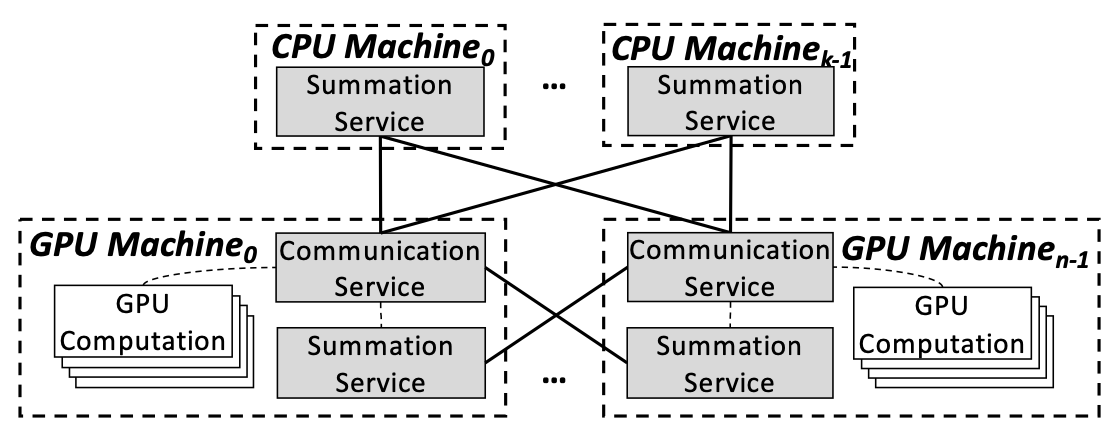
BytePS:加速异构集群中分布式训练的统一架构
本文介绍了BytePS,是字节跳动、清华大学和Google合作的项目,提出一种分布式DNN训练的统一架构BytePS,并延续了字节跳动在RDMA方面的研究,利用了RDMA高速网络的特性对集群的通信和算力资源利用率进行优化。
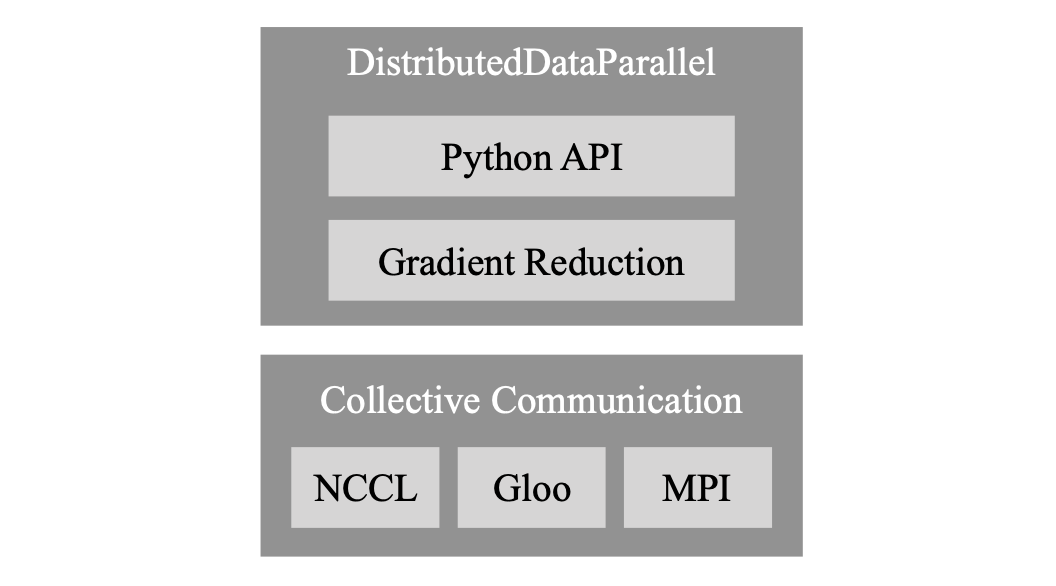
PyTorch Distributed:加速数据并行训练的经验
本文介绍了PyTorch DDP模块的设计、实现和评估。
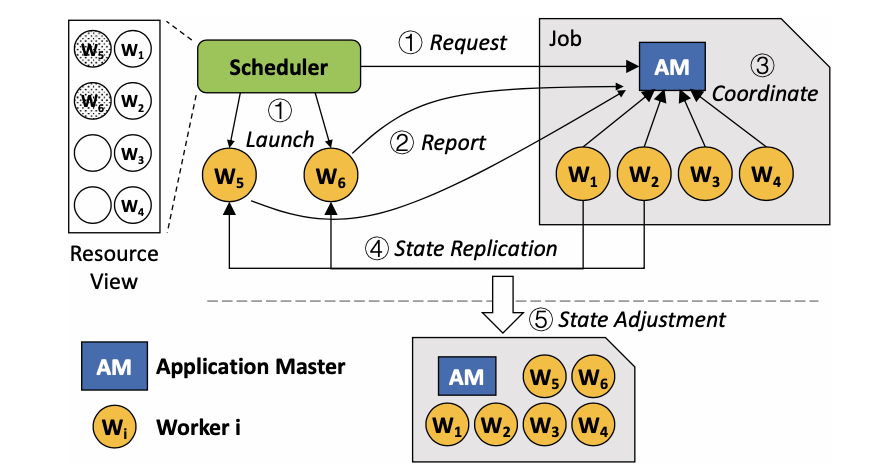
Elan: 面向深度学习的通用弹性训练
本文是Gandiva的后续工作,提出了一个可以保证异构GPU集群中深度学习任务效率和用户间公平性的调度方法。
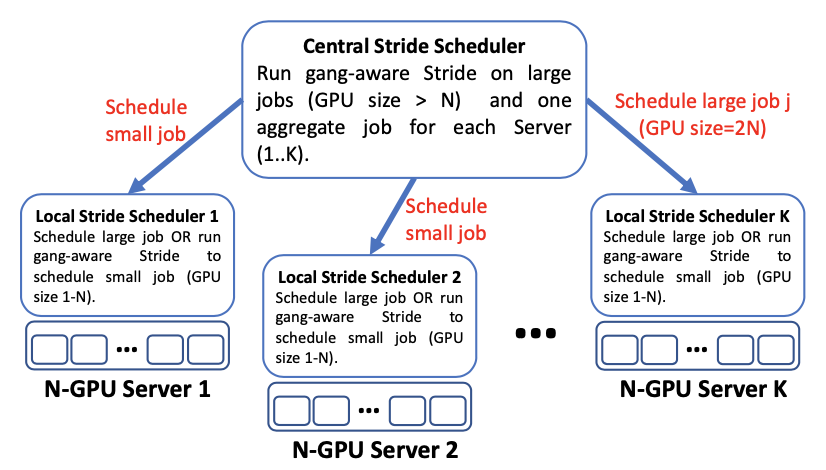
在异构GPU集群中权衡效率与公平性
本文是Gandiva的后续工作,提出了一个可以保证异构GPU集群中深度学习任务效率和用户间公平性的调度方法。
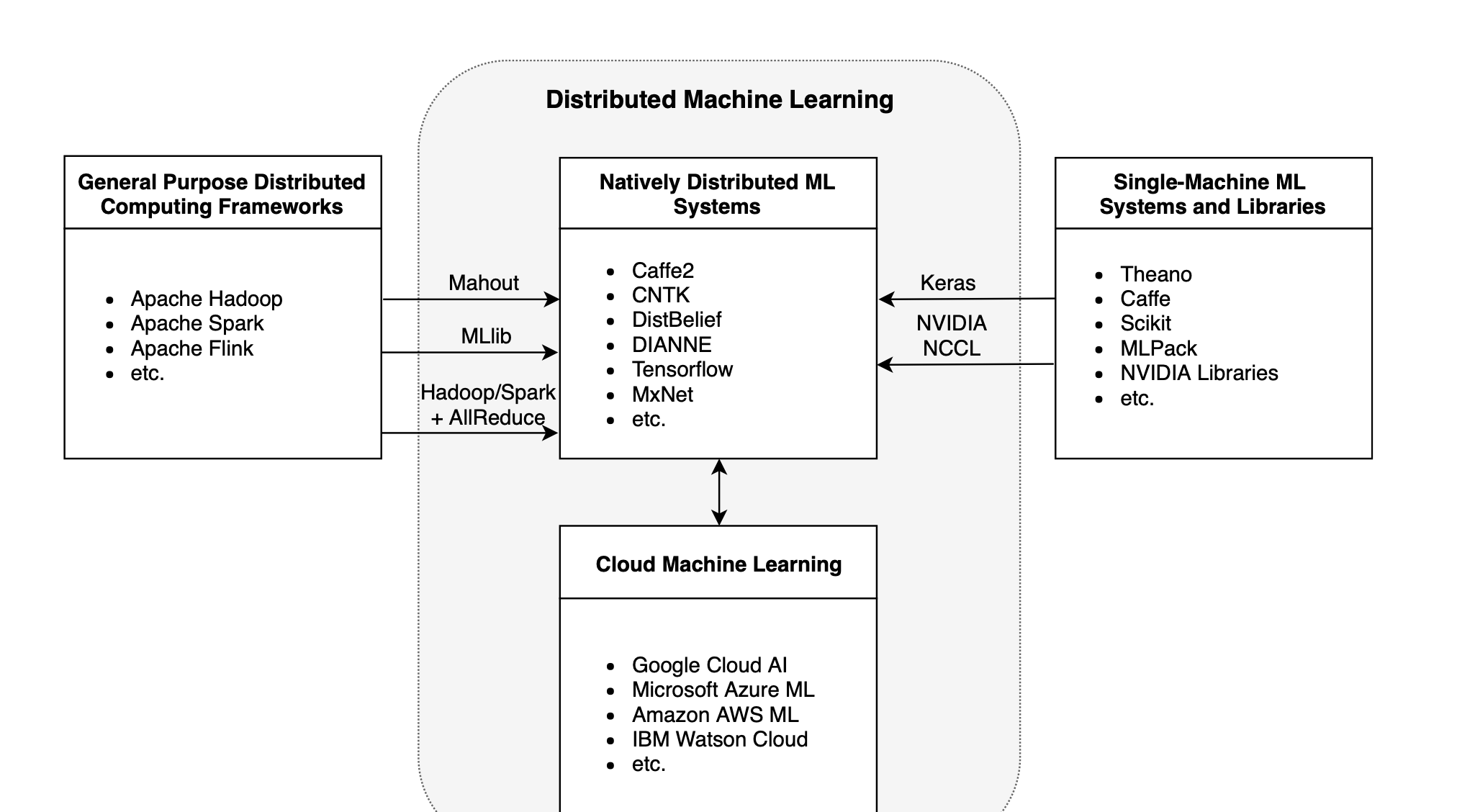
Surveys on ML/DL
总结与深度学习相关的Survey,主要是分布式机器学习和深度学习框架相关。
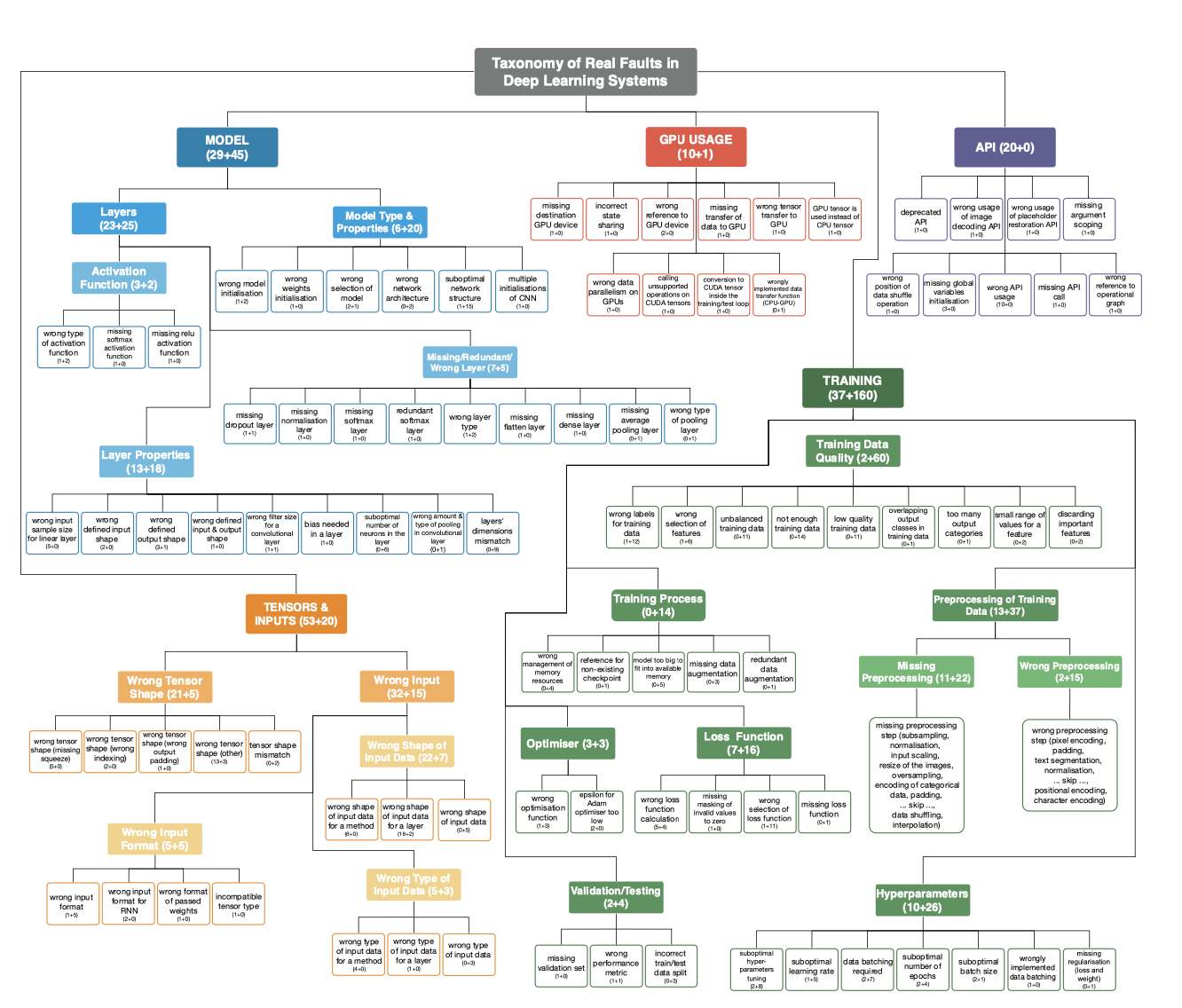
Empirical Studies on DL and Other Areas
总结与深度学习相关的Empirical Study,以及其他领域中类似的Empirical Study。
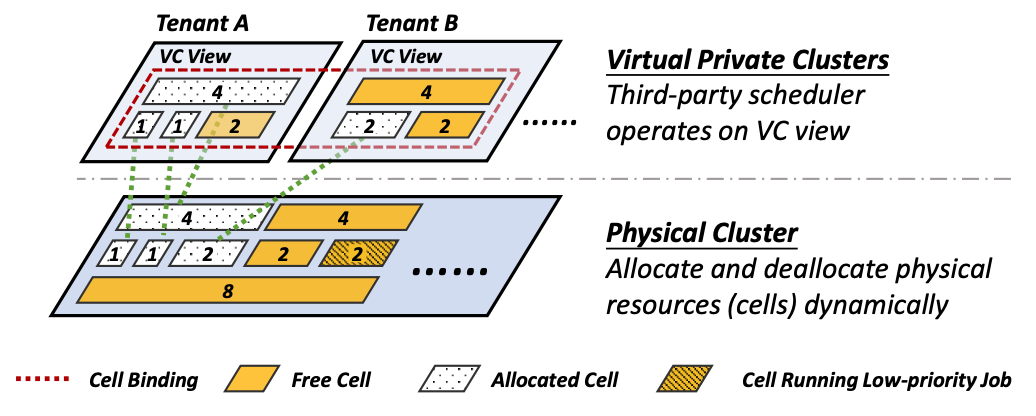
HiveD:新的多租户GPU集群管理方案
随着深度学习训练需求的不断扩张,很多组织和机构都会选择自建多租户集群来共享昂贵的 GPU 资源。然而现有的 GPU 集群管理方案因为使用了 GPU 配额(Quota)机制,可能导致严重的共享异常(Sharing Anomaly)现象:某些租户的深度学习任务甚至比在私有集群中性能更差。为了从根本上解决该问题,本文提出了一个新的多租户GPU集群管理方案HiveD,通过新的资源抽象和调度框架从而100% 保证共享安全(Sharing Safety),同时不失一般性地和任何任务调度策略兼容。




