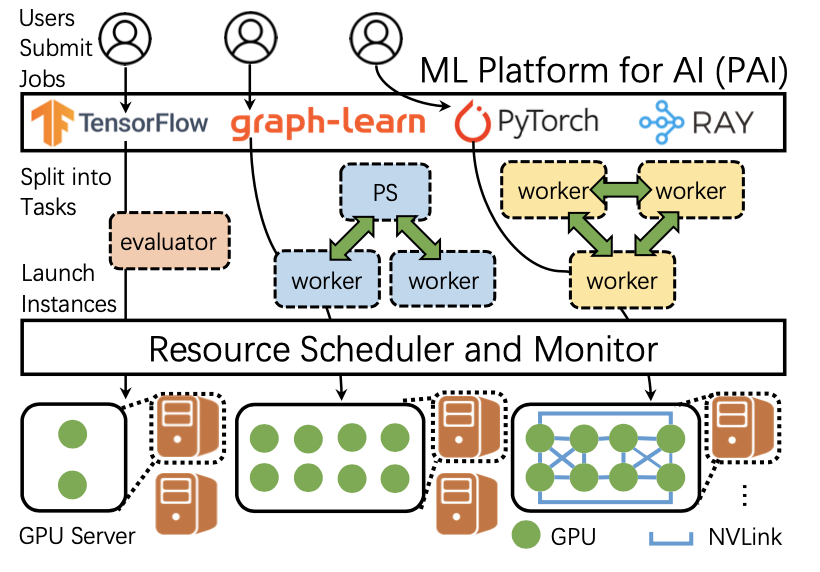
TOPOOPT: Co-optimizing Network Topology and Parallelization Strategy for Distributed Training Jobs
如今的DNN训练系统建立在传统数据中心集群的基础上,交换机以多层胖树拓扑结构(Fat-tree)排列。胖树拓扑忽略流量的特征,服务器对之间的带宽和延迟一致。当工作负载不可预测且主要由短传输组成时,是一种理想的网络拓扑结构;但是胖树网络是分布式DNN训练工作负载的瓶颈:根据Meta的生产环境中,网络overhead占据训练时间的60%。由于DNN训练的通信流量特征是可预测的,可以根据这个特点协同优化网络拓扑和并行策略。
动机
DNN训练的特点
数据并行时分布式训练中的一种常见做法,进行数据并行时不同工作节点之间通常以参数服务器、ring-AllReduce 、tree-AllReduce等拓扑结构进行通信。此外,单个GPU的内存无法容纳大型DNN模型,因此需要使用模型并行性将模型划分到多个GPU上。此外,由于跨GPU同步模型参数的成本越来越高,纯数据并行性对于大型训练作业来说很不理想,因此,人们使用数据和模型并行的混合来分布大型DNN,其中DNN的不同部分及其数据集在不同的GPU上并行处理。
每个训练迭代都包括两种主要类型的数据依赖关系。(1)在正向和反向传播期间计算的激活和梯度数据;(2)一旦处理了一批样本,就通过AllReduce步骤在加速器之间同步模型权重。根据并行化策略,这些数据依赖性可能产生本地内存访问或跨GPU流量。下文将类型(1)产生的网络流量称为MP传输,将类型(2)产生的网络流量称为AllReduce传输。
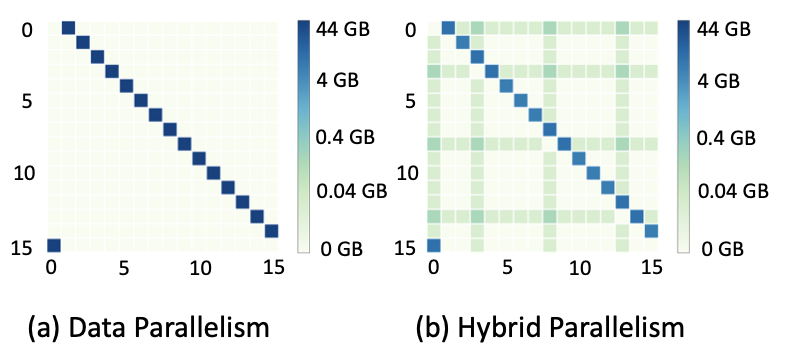
以深度学习推荐模型(DLRM)为例,如果模型有4个embedding表,embedding具有512列、10^7行,只采用数据并行的时候,会产生44GB的AllReduce数据传输,但是如果采用混合并行,最大的数据传输量只有4GB。因此,数据并行和模型并行结合对于大型模型来说十分必要。
生产环境数据分析
图2展示了Meta产业环境中的网络overhead,随着GPU数量的增加,网络很快占据了训练迭代时间的很大一部分。网络开销占Meta生产环境中DNN训练迭代时间的60%。这个瓶颈表明,现有的数据中心网络不足以满足新兴的DNN训练的工作负载。

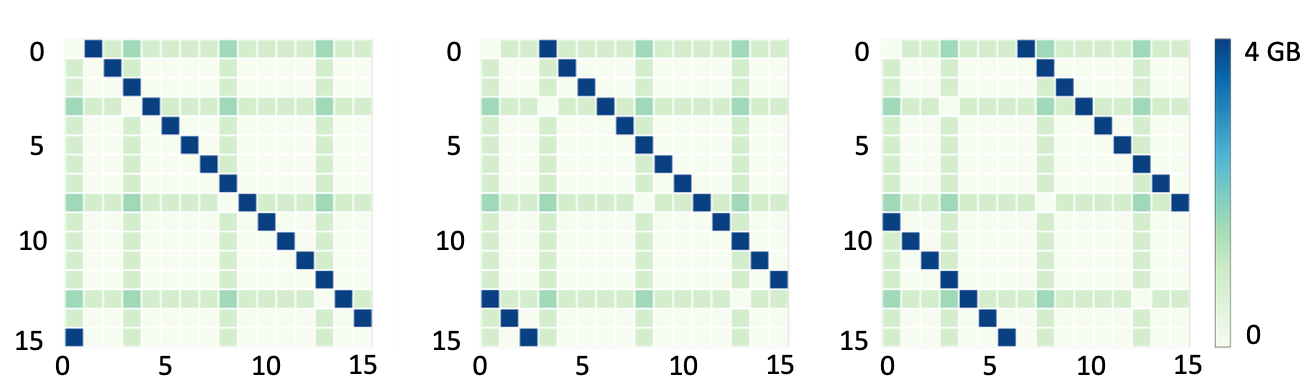
图3展示了Meta生产GPU集群中运行的四个训练作业的服务器到服务器流量的heatmap。图中的所有heatmap都包含对角线上的正方形(深蓝色),这表示服务器之间的环形通信模式。但是MP传输(浅蓝色和绿色方块)取决于模型,因为MP传输取决于训练作业的并行化策略和设备放置。在整个训练过程中,不同的迭代之间,训练作业的流量模式是一样的。

系统设计
本文提出的TOPOOPT是一种基于光学设备的新型系统,它联合优化DNN并行策略和拓扑结构,以加速训练作业。
TOPOOPT集群是一种可分片的直接连接结构,其中每台服务器都有d个接口连接到d个光交换机的核心层,如图4所示。光交换机使TOPOOPT能够将集群分片,产生每个训练作业的专用分区。每个分片的大小取决于作业申请的服务器数量。给定DNN训练工作和一组服务器,TOPOOPT首先离线在服务器之间找到最佳并行化策略和拓扑结构;然后,TOPOOPT重新配置光交换机以实现作业的目标拓扑。
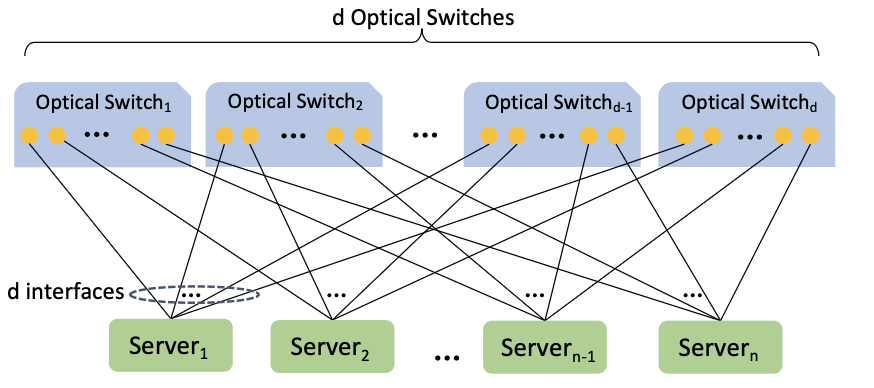
此外,本文使用了Host-based forwarding等现有工作使用了的优化方法优化网络。
算法设计
单独寻找最优并行策略是一个NP-complete的问题,网络拓扑和路由使得问题更加困难。
TOPOOPT将搜索空间分成两个平面:Comp.×Comm. 和Comm.×Topo.。本文交替优化,在一个平面中迭代搜索,同时保持另一个平面的结果不变。图5说明了交替优化框架:TOPOOPT使用FlexFlow的MCMC(马尔可夫链蒙特卡罗)搜索算法,在考虑通信成本的同时,为给定网络拓扑找到最佳并行化策略。如果并行化策略提高了训练迭代时间,TOPOOPT将其提供给Comm.×Topo.平面,使用TOPOOPT的TOPOLOGY FINDER算法找到有效的网络拓扑和路由。然后将发现的拓扑反馈到Comp.×Comm.。这进一步优化了基于新拓扑的并行化策略和设备布局。该优化循环重复直到收敛或k次迭代之后,其中k是可配置的超参数。

TOPOOPT有两个目标:(i)为AllReduce传输分配充足的带宽(因为大部分流量属于AllReduce);(ii)确保MP传输的跳数较小。这两个目标是可以同时实现的,因为DNN训练流量具有一种独特的特性——AllReduce流量是可变的。
例如,图6展示了三种不同的AllReduce链接方式,它们对应的traffic heatmap分别如图7所示。蓝色的AllReduce通信的位置是可以变化的,但是MP传输的heatmap保持不变。
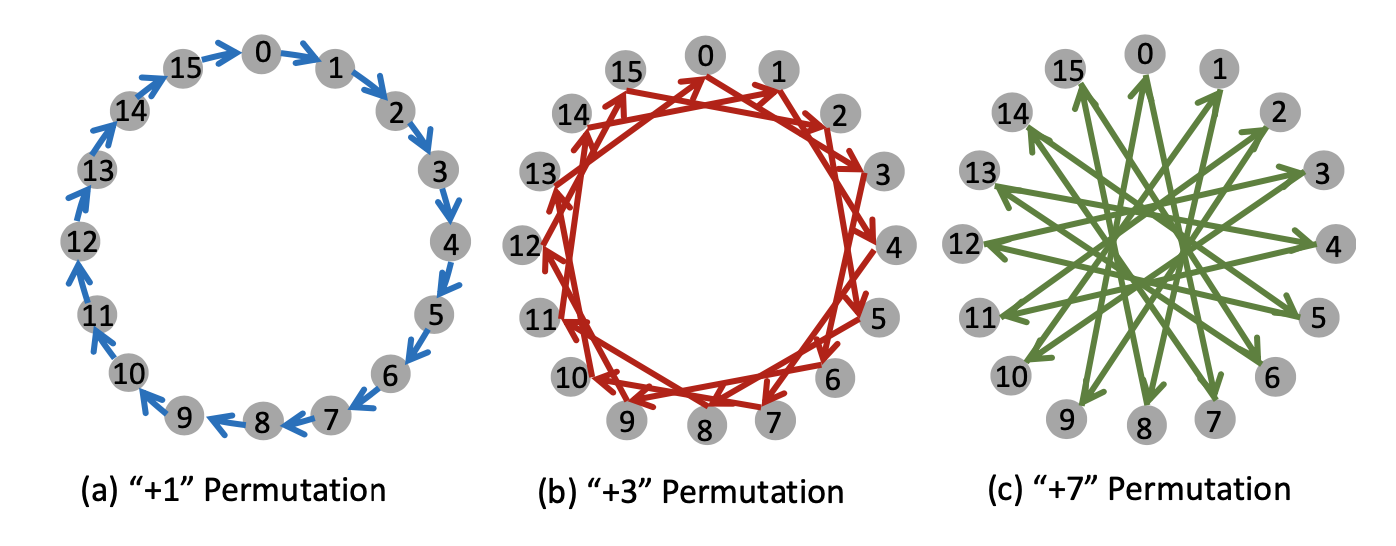
流量易变性意味着,如果一组服务器按特定顺序连接,只需重新排列服务器的标签,就可以得到另一种顺序,以相同的延迟完成AllReduce操作,同时可能为MP传输提供较小的跳数。TOPOOPT不是只选择一个AllReduce顺序,而是为每个AllReducer组找到多个排列,并与它们对应的子拓扑重叠。这样,TOPOOPT可以有效地服务AllReduce流量,同时减少MP传输的跳数。
为了减少所有可能排列的搜索空间,本文设计了TotientPerms算法,以基于群论找到所有规则环(连续服务器的索引之间的距离相等的环)的生成法则。然后,SelectPermutations算法可以减少集群的直径,以利于MP传输。
实验验证
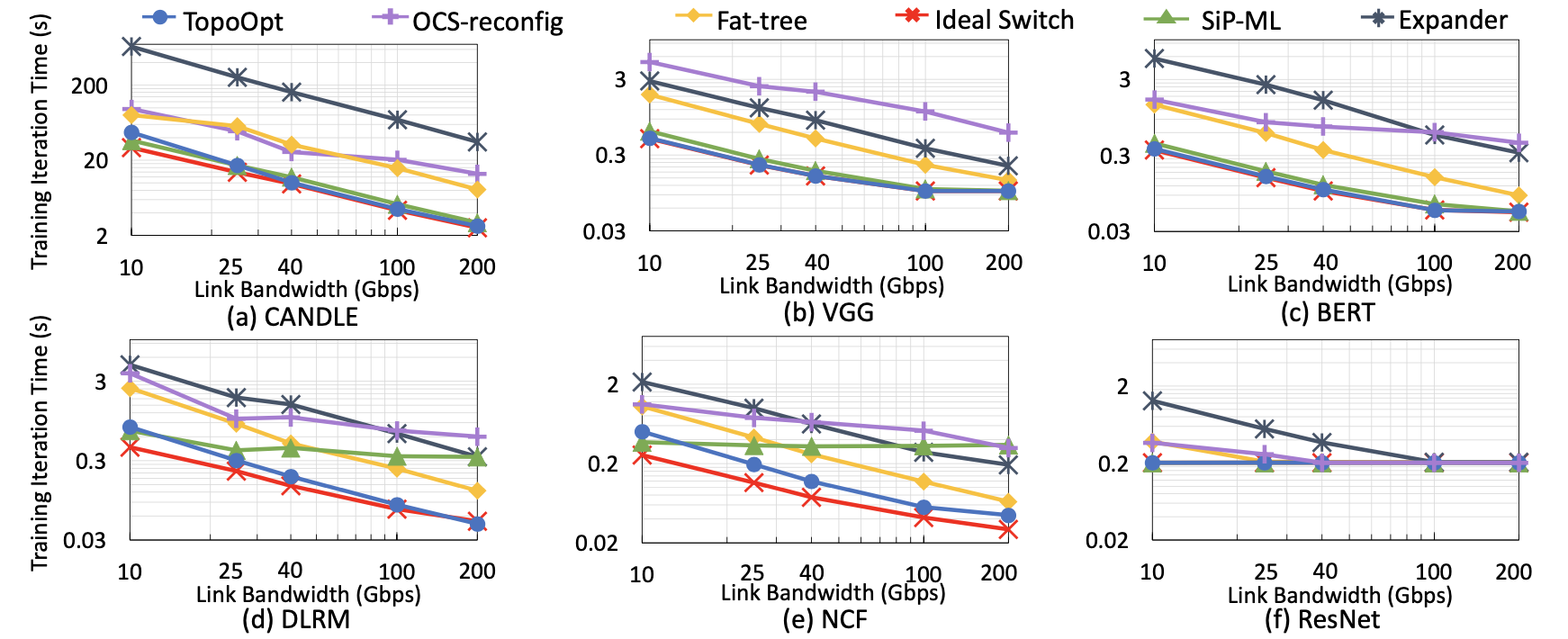
本文在6种不同的DNN模型上进行了模拟实验比较,其中DLRM和NCF模型的MP传输量更大。与成本相似的胖树拓扑相比,TOPOOPT将DNN训练时间减少了3.4倍。
原文作者:Weiyang Wang, Moein Khazraee, Zhizhen Zhong, Manya Ghobadi, Zhihao Jia, Dheevatsa Mudigere, Ying Zhang, Anthony Kewitsch
原文链接:https://arxiv.org/abs/2202.00433