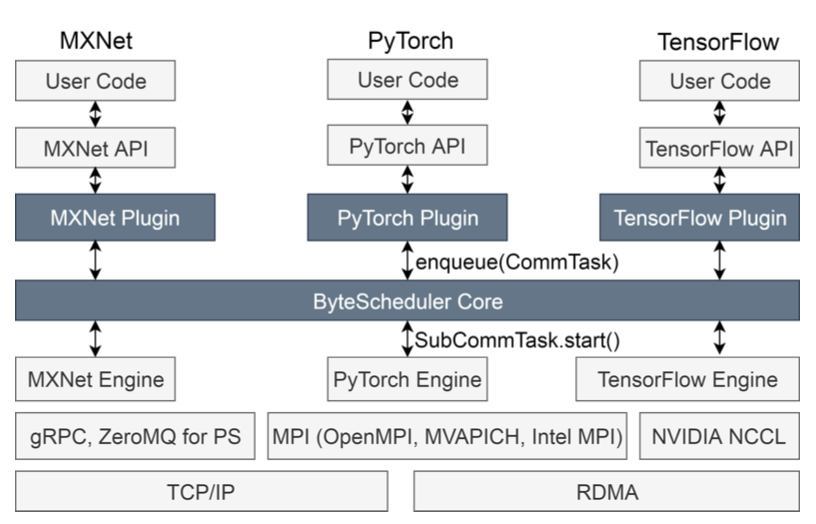
Carbon Emissions and Large Neural Network Training
简介
本文调查并分享这些最新和大型NLP模型的能耗和CO2e(CO2 equivalance emissions)估算值。通过描述硬件和数据中心上的实际搜索过程,本文还将Evolved Transformer的神经架构搜索(neural architecture search,NAS)的CO2e早期估计值减少了88倍。
本文对CO2e的调查揭示了对DNN生命周期、运行它们的数据中心和硬件、能量组合的变化以及准确评估CO2e的困难的不同于以往认知之处和误解。值得注意的是,本文测评了运行中的计算机和数据中心的CO2e,而不是制造或者回收它们CO2e。
为了让ML社区更容易理解训练的实际影响以及如何减少训练的影响,本文呼吁:
- 本文呼吁更多的研究者测量能源的消耗并公开相关数据;
- 除了准确率和相关的指标以外,能源使用效率应该是发表计算密集型模型的ML研究的评估标准,因为最可持续的能源是你不使用的能源;
- 即使我们可以在云数据中心将CO2e降至零,减少训练时间也很重要,这既因为“时间就是金钱”,也因为更低的训练成本可以让更多人参与进来。因此,本文也支持让更多的研究人员公布训练时使用的加速器的数量及其训练时间,以鼓励在降低训练成本方面取得进展。本文作者相信,这些新的激励措施可能会导致一个良性循环,让ML从业者竞相增加收入。
NLP模型的资源消耗和碳足迹
跑一个机器学习所需要的电量是一个关于算法、实现算法的程序、运行程序所需处理器的数量、这些处理器的速度和耗电量、数据中心传递能量和冷却处理器的效率、能源供应组合(新能源、燃气、煤等)。
很多公司在DNN模型inference上小号的能量比训练要多。比如NVIDIA估计80-90%的机器学习workload是在进行inference。Amazon Web 90%的云端ML服务是inference。因此很多公司专门为inference设计了加速器。本文主要关注training(training的耗能更独立且方便于探究),但是inference中的耗能也是不可忽略的。
表1为CO2e分解,本文之后将进一步解释这些改进的业务原理,展示了提高ML效率的交叉激励。
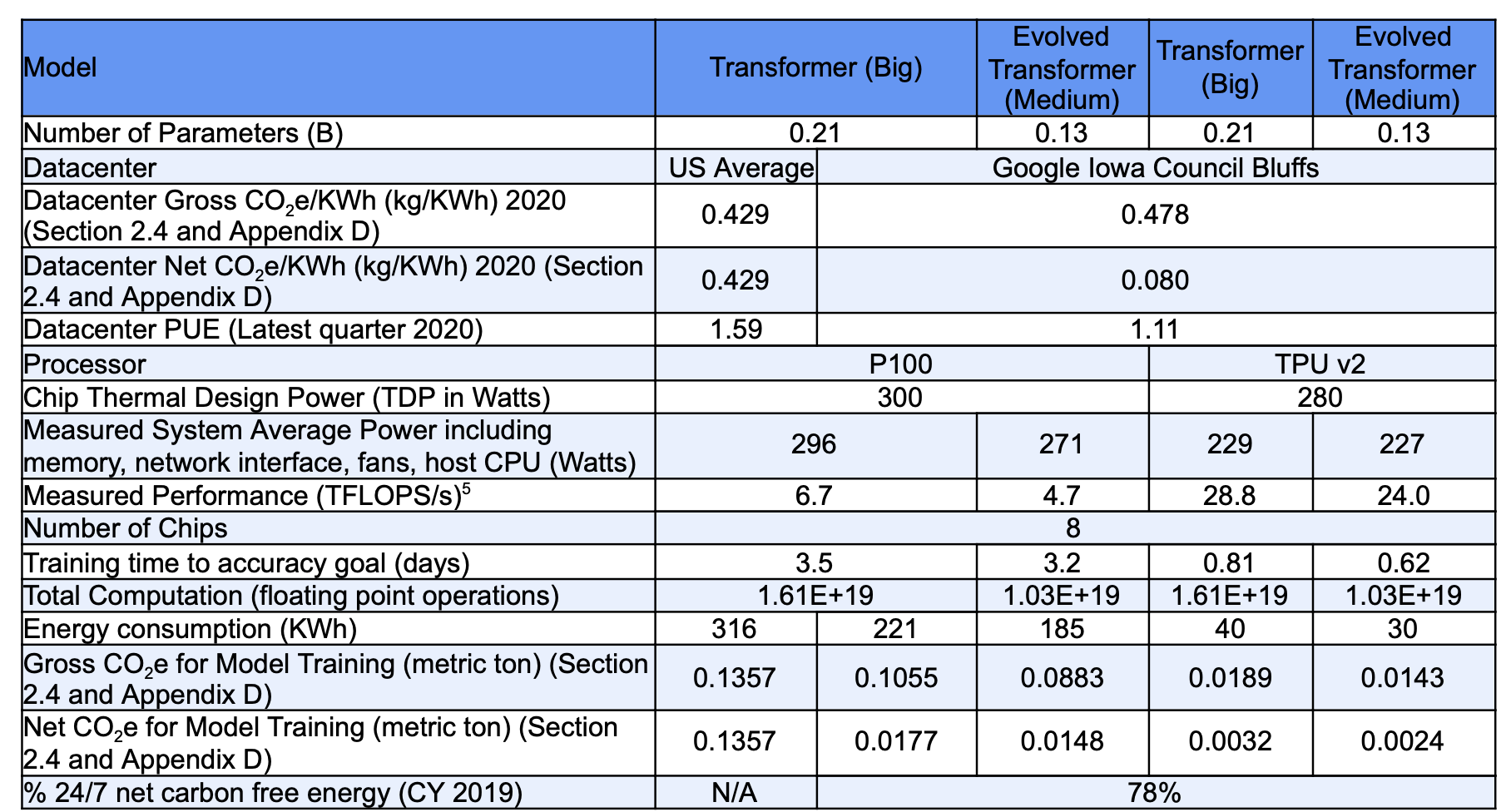
图1说明了每一步的收益:CO2e的总体改善为57倍。这一巨大的收益说明了为什么选择DNN模型、处理器、数据中心和地理位置对于改善二氧化碳排放至关重要。
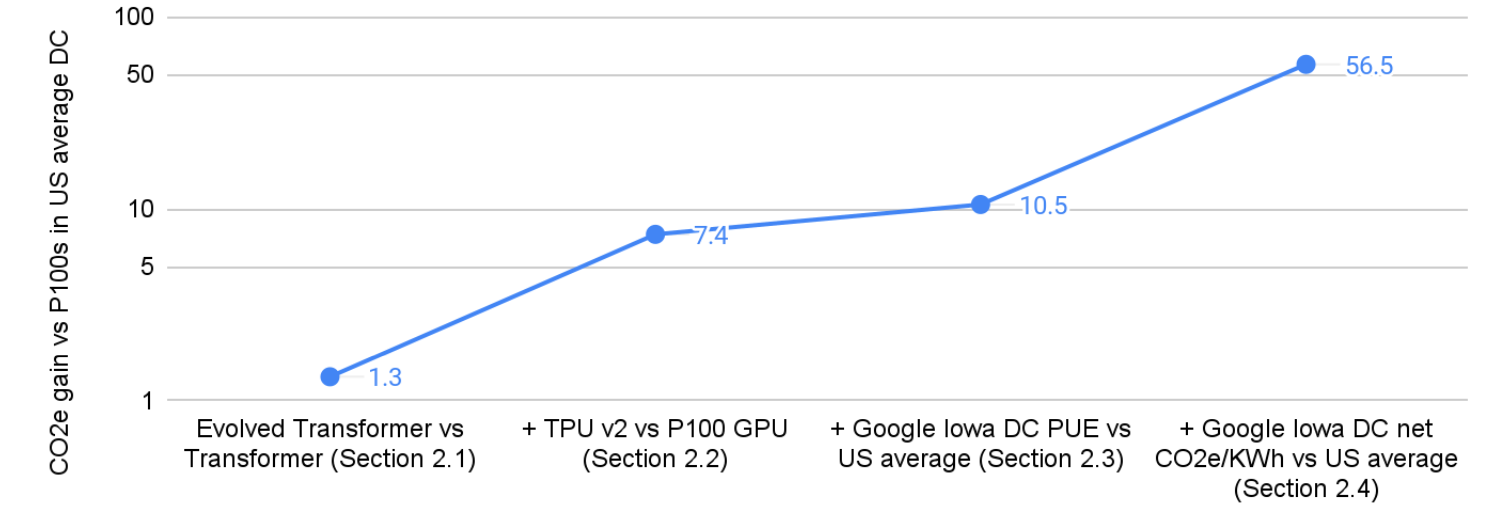
算法/程序的提升
和Transformer比起来,使用了NAS的Evolved Transformer训练更快,准确率略高。
商业原则:更快的训练不仅可以节省ML科研工作者的时间,还可以为他们的组织节省资金,减少CO2e排放。
处理器的提升
TPU比P100 GPU训练更快,且消耗的能源更少。
商业原则:在过去十几年中,深度学习的范围和规模大幅增加,这为构建定制硬件创造了机会,该硬件可根据DNN模型训练和inference所涉及的计算类型进行定制。在过去的七年中,谷歌没有像许多其他组织那样使用GPU,而是为DNN设计、构建和部署了四代定制张量处理单元(TPU)硬件,以加速模型训练和inference。为了获得更好的投资回报,云计算公司的目标实际上是提高性价比,而不仅仅是性能。这里的成本是指总拥有成本(TCO),包括年度运营成本,如耗电量和计算机、冷却、配电和建筑的资本支出摊销。功耗与TCO几乎完全线性相关,因此提高性能/TCO也有助于性能/瓦特,节省资金并减少CO2e排放。
数据中心的提升
衡量数据中心效率的一个指标是它超出了数据中心内计算设备的直接动力的能量开销。由于服务器利用率等其他因素的影响,云数据中心的能效大约是典型企业数据中心的2倍。更广泛地说,由于云数据中心比典型的企业的数据中心的能效要高得多,数据中心能源使用量并没有激增。最近发表在《科学》杂志上的一篇论文发现,尽管计算能力在同一时期增加了550%,但全球数据中心能耗与2010年相比仅增加了6%。
商业原则:云计算公司致力于节能数据中心,因为它可以节省资金并降低排放。“能量就是金钱。”
能源供应组合的提升
根据美国平均能源供应组合,能源的总碳强度为0.429kg CO2e/千瓦时。在按照谷歌的24/7无碳能源框架匹配谷歌的清洁能源购买后,作者在爱荷华州数据中心运行Evolved Transformer的净CO2e下降到0.080,比原来的好5.4倍。
商业原则:与通过光纤以光子形式发送信息相比,远距离传输电力成本更高,效率更低。云计算允许像谷歌这样的公司拥有一个全球数据中心组合,其中许多位于电网更清洁的地方(如芬兰)或公司可以直接购买清洁能源的地方(如爱荷华州)。2020年,谷歌在其能源战略中宣布了一个新目标:到2030年,它的目标是让所有谷歌数据中心和办公室全天候使用无碳能源。对于这个24/7无碳能源核算,作者从每小时消耗量中扣除在同一地理位置的本地电网和同一小时购买的所有清洁能源,从而得出净CO2e/KWh值。由于爱荷华州夜间风力强劲,谷歌的风力发电组合将爱荷华州数据中心2020年12月的CO2e/KWh总平均值降低了6倍,从当地电网的0.478千克降至净平均值0.080千克。
总结
$$
KWh = (Hours\ to\ train) \times (Number\ of\ Processers) \times (Average \ Power \ per \ Processor) \times PUE \div 1000
$$
$$
tCO_2e = KWh \times kg \ CO_2e \ per \ KWh \div 1000
$$
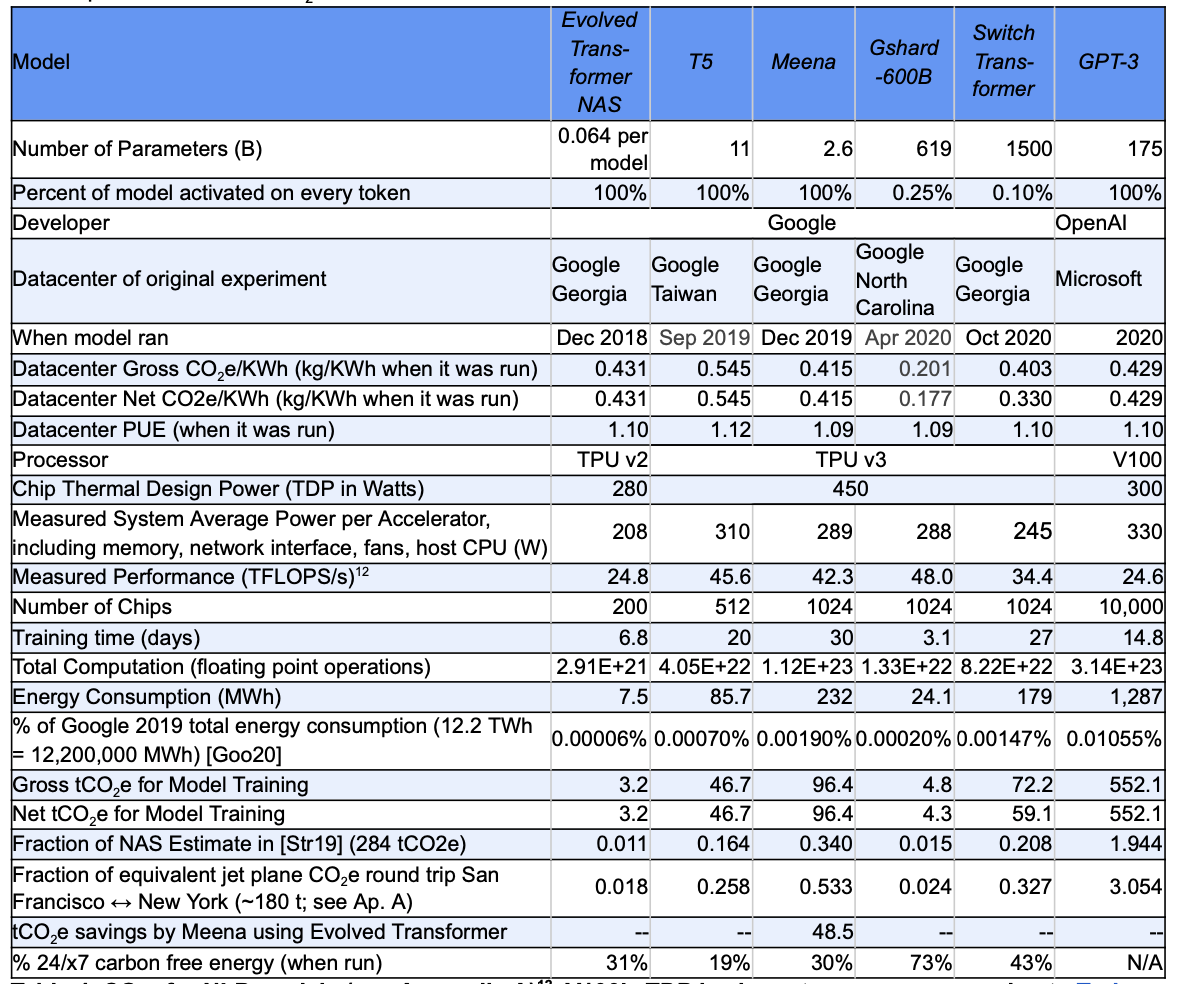
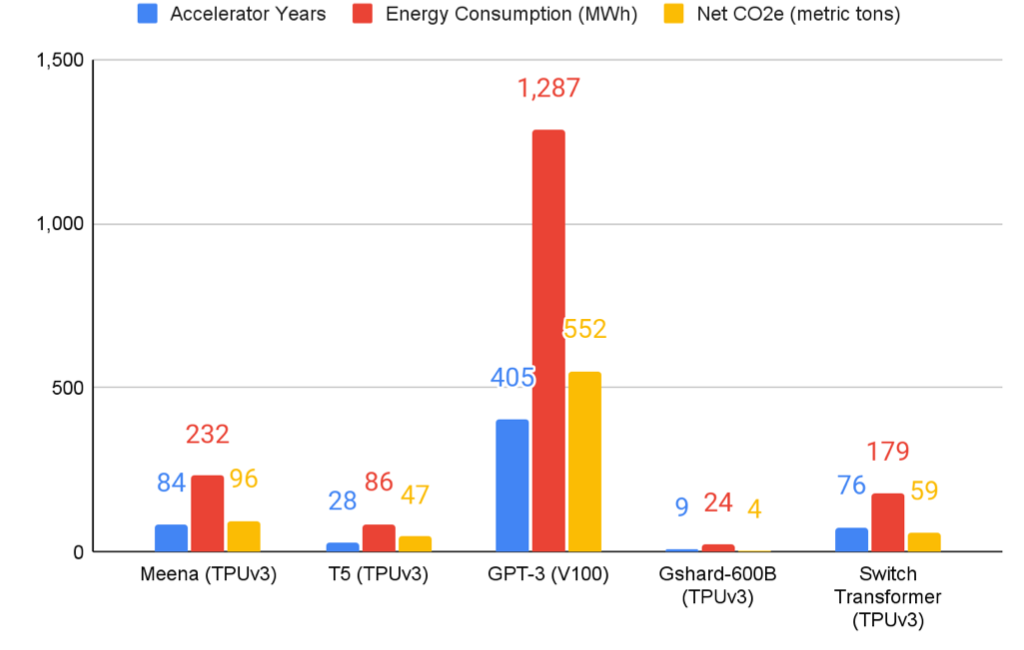
5种大型NLP模型的C能源使用和CO2e排放
- T5: 86MWh, 47tCO2e。
- Meena:232MWh, 96tCO2e。
- GShard:24MWh, 4.3tCO2e。
- Switch Transformer:179MWh, 59tCO2e。
- GPT-3:552MWh, 1287tCO2e。
讨论
在本节中,作者讨论因训练NLP模型而产生的与碳排放相关的其他因素。
估计NAS的能量消耗
使用NAS后,模型参数减少37%,训练收敛所需时间减少25%,CO2e排放量减少48.5t。
整个训练过程中消耗的能源远远不止最后一次训练所消耗的能源
作者认为ML从业者可以研究整个训练模型的生命周期,制定经验法则,根据最终训练成本估算总体碳足迹。
测量比推测更有趣
虽然对碳排放量做出估计相对容易,但我们应更多地关注已经进行的实际实验,而不是假设的案例研究。无论是处理器还是DNN,实际测量情况和理论情况都有很大不同。
标准的ML算法技术可以提高能源效率
有许多算法技术可以提高机器学习模型的能量效率。有些技术可以用较少的总体计算达到相同的精度。另外有的技术可以使用一个已经训练过的大型模型作为起点,生成一个重量更轻、计算效率更高、精度几乎相同的模型。这些技术都有助于减少计算成本,从而减少模型的能源和碳排放。这些技术包括知识蒸馏、剪枝量化高效编程、迁移学习与微调、稀疏激活的专家风格混合的模型等。
即使在同一个组织里,使用哪一个数据中心很重要
作者发现在何时何地训练DNN非常重要。此外,该方案可能是ML从业者减少CO2e排放的最简单途径。
许多人都可以访问能源优化的数据中心
自2010年以来,云计算的使用量不断增加,数据中心的能源强度每年降低20%。访问能源优化、低成本的云数据中心并不局限于少数公司的员工;世界各地的人们可以使用阿里云、亚马逊网络服务、谷歌云平台和Microsoft Azure等服务租用服务器。此外,阿里巴巴、亚马逊和谷歌还通过云服务提供对其自定义DNN处理器的访问。自2010年以来,公共云的业务年增长率高达50%,这表明公共云非常受欢迎。许多人认为,云在成本和能源方面的效率意味着它是所有数据中心的最终未来。
训练成本也很重要
尽管许多人可以使用这些相对高效的计算资源,云公司在未来可能会大幅减少碳足迹,但降低训练的经济成本仍然很重要。显然,节约资金对每个人都很重要,但NLP模型的昂贵的训练成本也使许多研究人员无法实现这种研究。与环境问题一样,获取最先进模型的不平等性是另一个强有力的动机,它可以激励研究者开发高效节能的ML模型,且该模型的计算能力要与其他模型一样强。
训练大型NLP模型与其他活动相比如何?
作者将训练NLP模型的能量消耗与航空飞行、比特币做了比较。
训练这四个大型NLP模型并不是谷歌能源消耗的重要部分。
NLP模型带来的效益值得所需的能量消耗吗?
MoE模型越大,BLEU分数的获益越大。
训练模型的分摊人均CO2e影响小于发送一条短信的CO2e。
原文作者:David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean
原文链接:https://arxiv.org/ftp/arxiv/papers/2104/2104.10350.pdf