Blink: Fast and Generic Collectives for Distributed ML
动机
目前用于深度学习的数据集规模越来越大,在训练效果得到提升的同时,与之同时,漫长的训练时间却成为了另一个让人头疼的问题。基于多个 GPU 的数据并行训练(Data-Parallel Training)大大缓解了大规模深度学习模型训练耗时长的问题,但是数据并行需要同步模型参数,跨 GPU 的参数同步在大规模训练时产生了较大开销,这一开销成为了限制训练速度的瓶颈。
为了缓解通信上的这一瓶颈,这几年在软件和硬件上都有很大的提升。在硬件方面,NVIDIA提供了多种先进的服务器,例如DGX-1、DGX-2等。在这些服务器中,有GPU用于计算的P100或者V100,有用于通信的PCIe和NCLink。在软件层面,很多公司提供了自己的通信库,例如NVIDIA的NCCL,Facebook的gloo,还有Uber的Horovod。
作者发现,即使使用了当前很先进的的硬件,通信开销仍然很高。

而且,随着GPU的计算能力的增强,通信开销的带来的影响会越来越大。因此,作者认为,在现有的硬件条件下,我们需要可以更快进行通信的protocol。
为了减少通信开销,作者设计了Blink这一集合通信库。
挑战
- Different server configuration。图2中有两种DGX-1服务器link的拓扑和带宽不同。 目前的通信库通常会忽略这个问题,从而导致很多的link不能被高效利用。
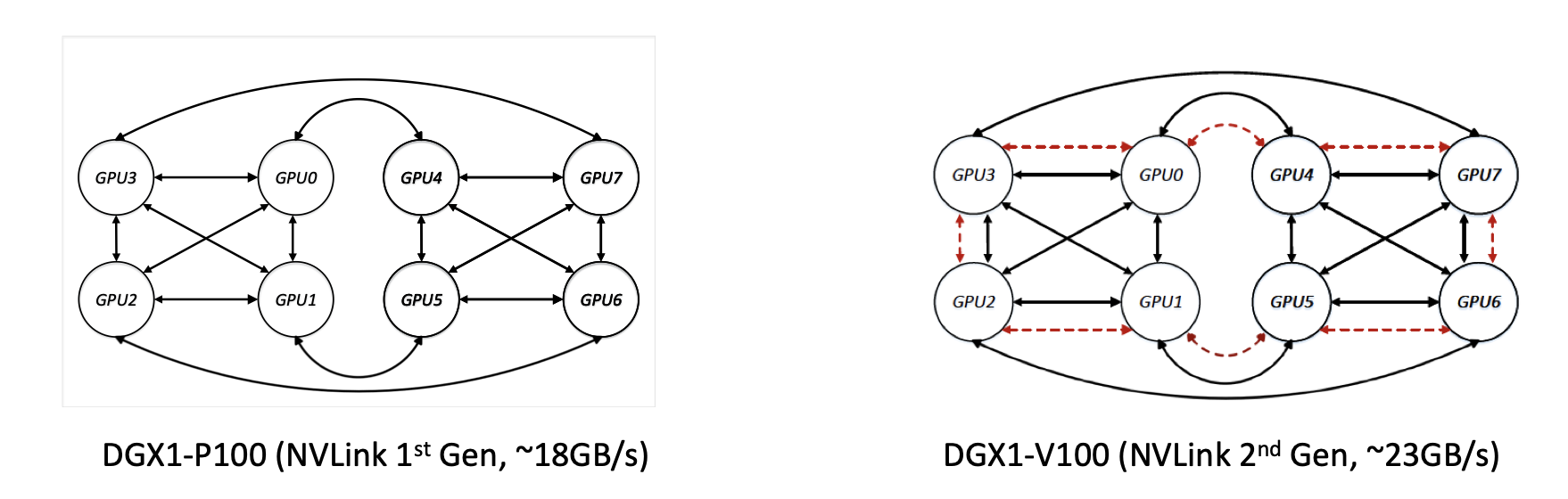 图2:两种DGX-1服务器的拓扑结构
图2:两种DGX-1服务器的拓扑结构
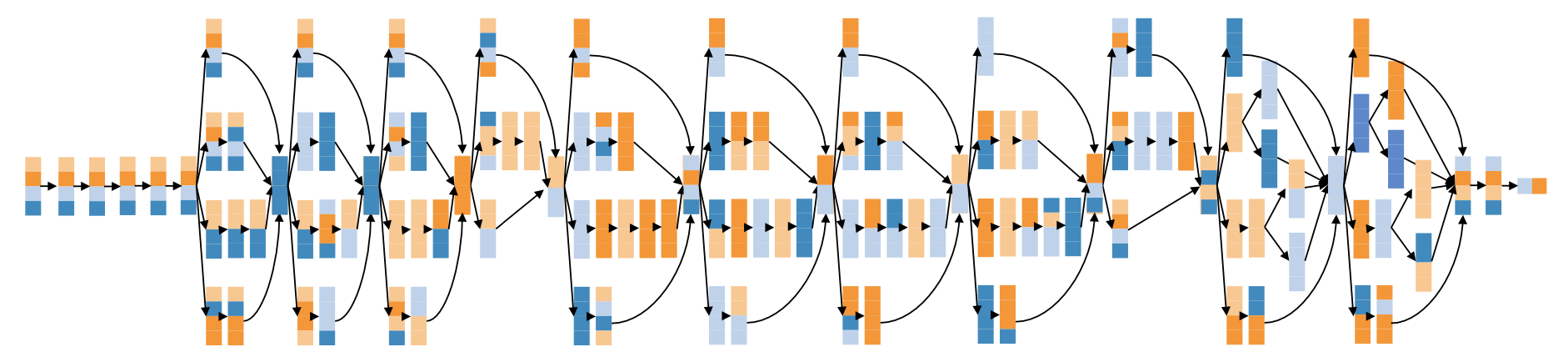
Link heterogeneoty。SOTA通信库的通信原语都是基于“环”结构的。那么什么是基于“环”的原语呢?以broadcast为例,左边有四块GPU,他们通过环形的拓扑连接起来。(broadcast的过程)而一个server中会有多种不同种类的link。(PPT图有pcie和nvlink)如果使用这种基于“环”结构的通信原语的话,他只能利用同种类型的link。如果使用了不同类型的link,通信过程中的bottleneck在于这个ring中bandwidth最小的那一个link(例如,pcie bottleneck)。
Fragmentation in multi-tenant clusters。 在多租户的集群中,由调度器把GPU分配给不同的job。有时候一个机器里会有多个job,这几个job之间有可能会共用PCIe或者某种link,从而互相影响。
在从微软收集到的的40,000多个job的trace中,可以看到,即使用户一般都会申请试用2的n次方块GPU,但是,在每个server中分配的GPU数量可能是3,5,6,7这种数字。比如一个使用8块GPU的job如果被分在2个server上,可能是2+6或者3+5这种数字的组合。为什么会有这种碎片化的问题呢?因为集群的调度器不是topology-aware的。目前还没有通用的、高效进行migration的方法,为了避免过长的queuing delay,这些DNN的任务必须面对碎片化的问题。在这种情况下,会有一些GPU的分配中,同一个job使用的GPU没法直接形成“环”(ppt图)。在NCCL中如果遇到这种情况,会使放弃使用贷款更高的NVLink,而去使用PCIe。
Workflow
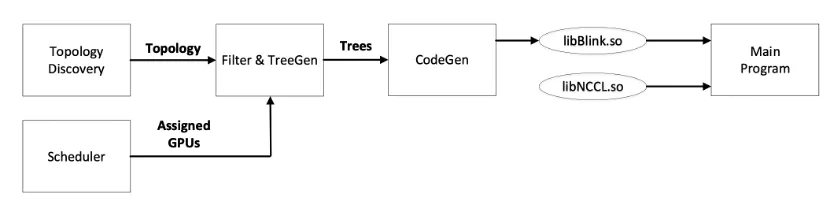
(1)给定深度学习任务,一旦安排并分配了一组 GPU,Blink 就能够探测机器的拓扑结构,并通过分配的 GPU 推断互连拓扑结构。
(2)给定拓扑,将集体通信操作建模为有向图上的流,并计算生成树的最大分数填充(TreeGen)此步骤输出一组生成树和对应于应通过它们发送多少数据的权重。
(3)CodeGen 解析生成树并生成 CUDA 代码。生成的代码与 NCCL 提供的 API 匹配,并打包到共享库 libblink.so 中。
(4)设置 LD_PRELOAD 标志,以便在调用主程序时动态加载 Blink 实现。这确保了现有程序可以在没有任何修改的情况下运行。
系统设计
TreeGen
packing max. spanning trees
将从分配的资源推断出的拓扑建模为一个有向图,其中每个 GPU 是顶点 V,每个链路(NVLink 或 PCIe)标记为有向边缘 E。每个有向边缘还具有带宽比例容量。通过找到图中的有向生成树或树状图的最大填充可以达到最优速率。每个树状图 Ti 从根涡生成,沿着有向链接扩展到其它涡点。通过确定满足能力限制的最大权重树状图,可以解决在广播中确定最佳时间表的问题。
由上式,给定一个图 G,顶点为 V,边为 E,根为 r,生成树为 T1, T2, T3, … Ti,希望找到权重 w_i,使得通过任何边的权重树的总和不超过特定边的容量。
如何生成这些树?MWU算法+一个新提出的算法[5],接近线性时间。
这样做的问题是,最优解种可能包含了太多的树。而且每个树中需要传输的数据量太小了,不能充分利用每一个link的带宽。
为了解决这个问题,新增一个限制条件:对于每一个link,要么不用这个link,要么把这个link的带宽用满。(181->6)
推广到多对多的情况
为了处理多对多的操作,作者利用了这样一个事实:在这些机器中发现的所有链接本质上都是双向的,因此可以创建一个无向图,用链接的一个方向运行多对一原语,并相应地在另一个方向运行一对多原语。allreduce = reduce+broadcast
(这种使用两个无向树的策略也与 AllReduce 操作所需的消息数下限相匹配。
AllReduce 的进程需要发送的最小消息数是 2x|(N-1)/N|。N 个顶点上的生成树包含 N-1 条边,并考虑了两个方向上的树(一个用于 Reduce,一个用于 Broadcast),类似的,本文方法同样有 2x(N-1)条消息。)
CodeGen(implementation)
通过pipeline减小数据传输的延迟。并通过前几个iter的profile选取合适的chunck size。
实验评估
在实验评估环节,作者将Blink与目前最先进的、基于环的集体通信协议(如 NCCL2)相比较。实验结果表明,Blink 可以实现高达8倍的模型同步速度,并将端到端DNN模型训练时间减少 40%。
原文作者:Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee, Jorgen Thelin, Nikhil R. Devanur, Ion Stoica
原文链接:https://arxiv.org/pdf/1910.04940.pdf
参考文献:
[1] MLSys提前看 | 机器学习的分布式优化方法, https://zhuanlan.zhihu.com/p/108289809