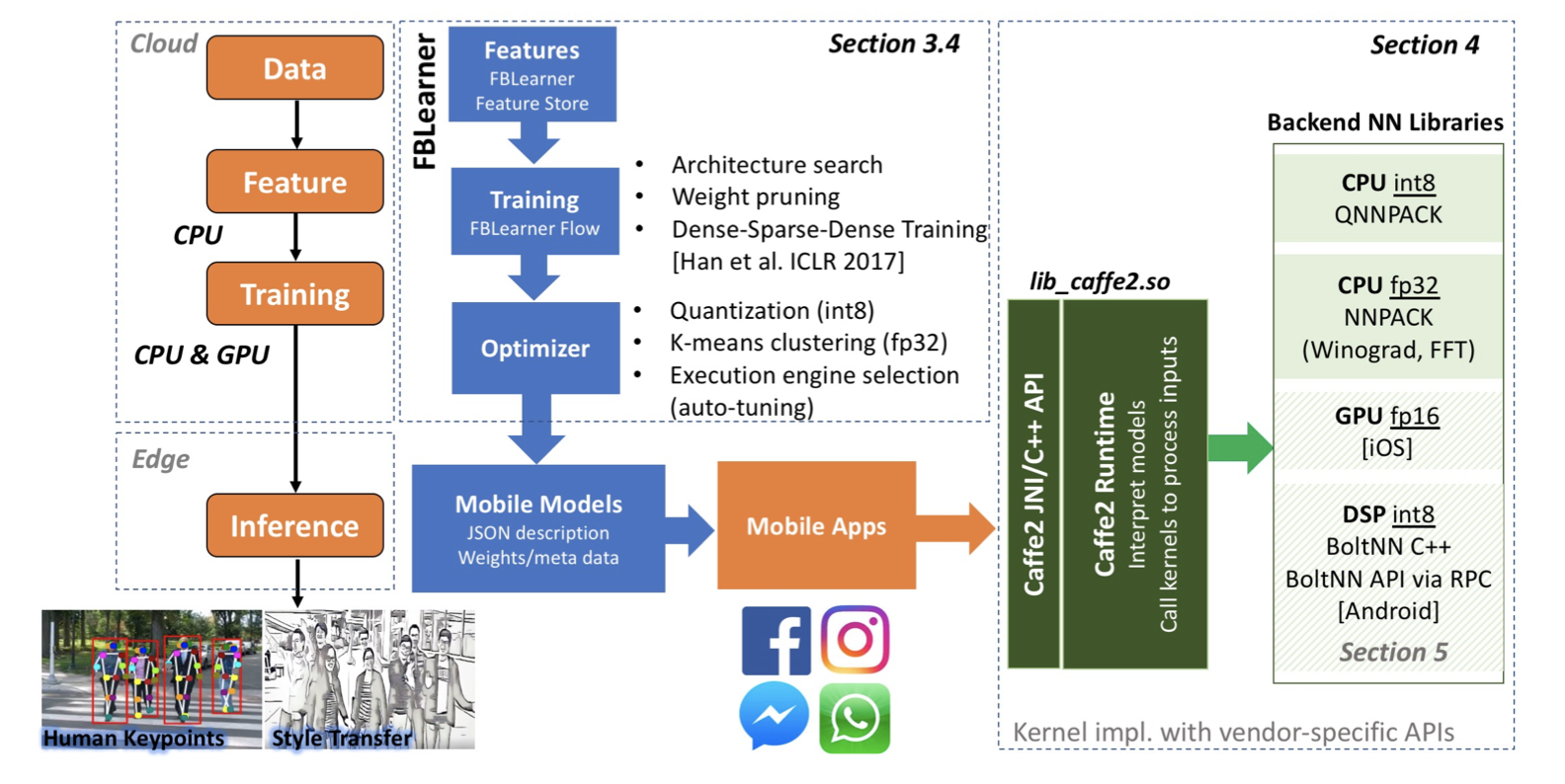
Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks
传统深度学习框架由于其自身的局限性,如今还远没有充分发挥出硬件的计算性能。微软亚洲研究院的研究员们在一些测试集上发现,现有的深度学习模型只能用到 GPU 2%到40%的性能。传统的深度学习框架通常通过分层调度来将一个深度学习模型调度到硬件设备(通常是 GPU 这样的协处理器)上进行计算。首先,在上层,深度学习模型通常会被抽象为由算子(Operator)和依赖关系构建而成的数据流图(DFG),深度学习框架主要负责将每个算子按照正确的依赖关系依次调度到下层设备上;接着,在下层硬件设备上(如 GPU),会有一个硬件的调度器将每个算子根据其内部并行性调度到硬件内的并行计算核上。这样两层调度的模型尽管较为简洁明晰,但在实际的部署中,两个调度层互相不感知会导致较大的调度开销,以及较低的硬件利用率。
传统深度学习框架在实现全面神经网络优化上的核心障碍在于:首先,现有的基于数据流图的抽象无法表示算子内部的并行性,对于由深度学习框架控制的图调度器完全是黑盒;其次,硬件厂商往往将细粒度的任务调度隐藏在硬件中,对上层框架调度也是黑盒。
针对现有深度学习框架的局限,微软亚洲研究院和北京大学、上海科技大学合作提出了一种可以成倍甚至几十倍地提升深度学习计算速度的编译框架RAMMER。这篇文章发表于OSDI 2020。
动机与挑战
目前,对两个层面的并行是通过“两层”的调度来进行的。DFG (data flow graph) scheduler实现inter-op的并行:通过op之间的依赖关系“发射”准备就绪的op;在不同的硬件上,op被看作是库中的“黑盒”function。硬件上的scheduler实现op内的并行:它把op内部的计算映射到加速器上的并行执行单元(EUs)上。在shchedule的overhead可以忽略且intr-op的并行计算可以充分利用全部的EU的情况下,这样两层的架构可以运行得很好。
然而,通常情况下,GPU设备的利用率会很低,调度op的开销也会很大。另外,这种两层的架构忽视了inter和intra op并行之间微妙的相互作用。比如两个可以同时计算的op可能尽可能地占用更多的EU资源,但是每个EU的利用率并不高。这会导致其中一个op等待另一个op执行完,才能获得足够的资源。
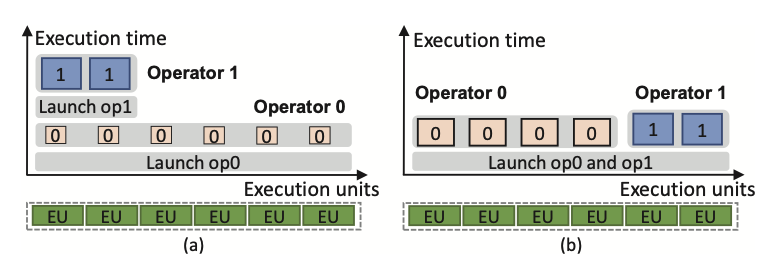
因此,Rammer把inter-op和intra-op共同进行调度。有几点挑战:
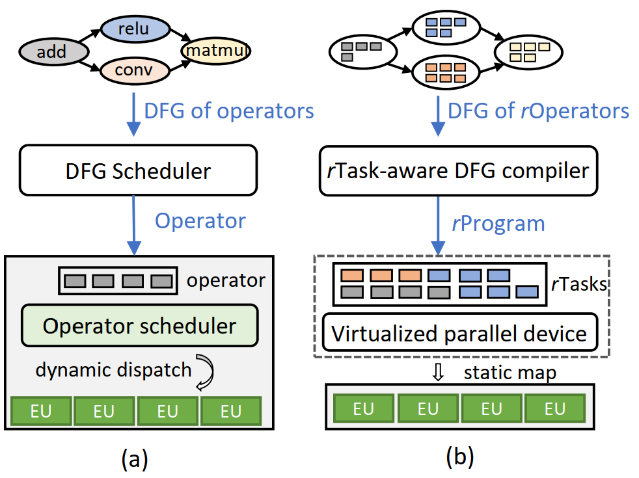
挑战1:op的intra-op并行是由硬件进行调度的,并没有给软件暴露出细粒度的intra-op并行计算方式
解决方法:定义了rTask作为在EU上计算的最小单元,并把细粒度的intra-op parallelism暴露出来
挑战2:GPU等加速器没有暴露intra-op调度的接口
解决方法:Rammer把硬件加速器抽象成虚拟的并行设备,把rTask调度到vEU上,每一个vEU再对应一个真实的加速器上的EU。
挑战3:细粒度的调度引入跟多的调度overhead
解决方法:多数DNN的计算图是“可预测的”,且op的performance是deterministic的。因此可以在编译阶段就生成执行方案
Wavefront scheduling policy
Rammer中为每一个op都实现了一种或多种kernel(具体的实现方式)。有的kernel计算很块(fast),有的kernel使用资源较少(resource-efficient)。Rammer默认使用fastest kernels;在资源比较紧张、可以占满所有EU的时候,使用resource-efficient kernels。
实验评估
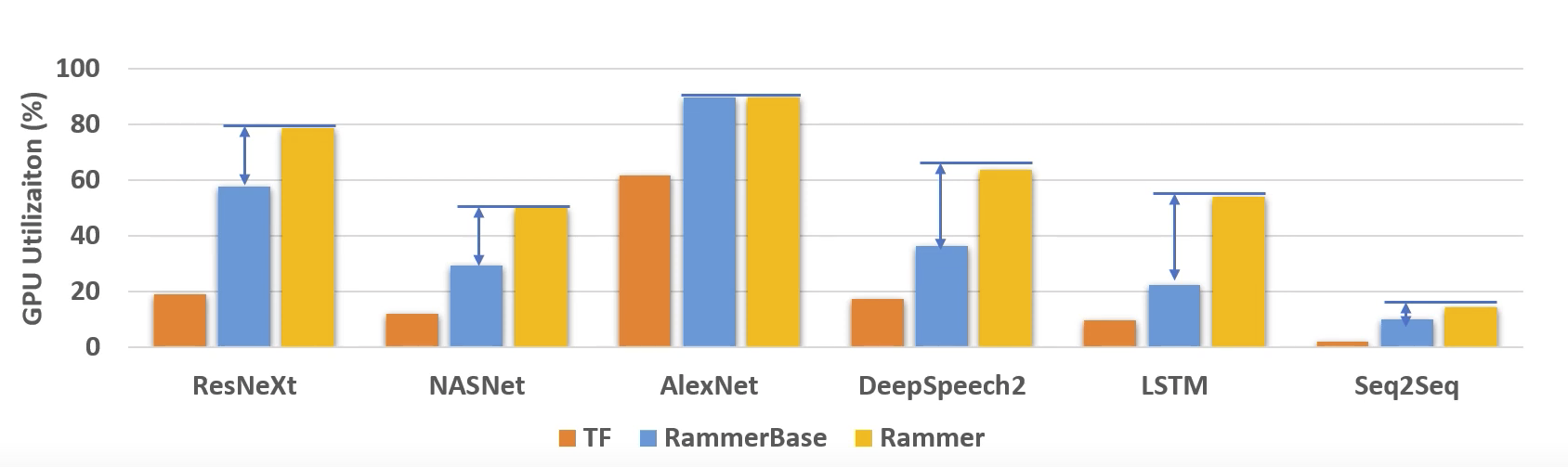
Rammer可以提高GPU的利用率,但是在某些情况下,讲两层的op并行调度架构改为1层的效果并不明显。
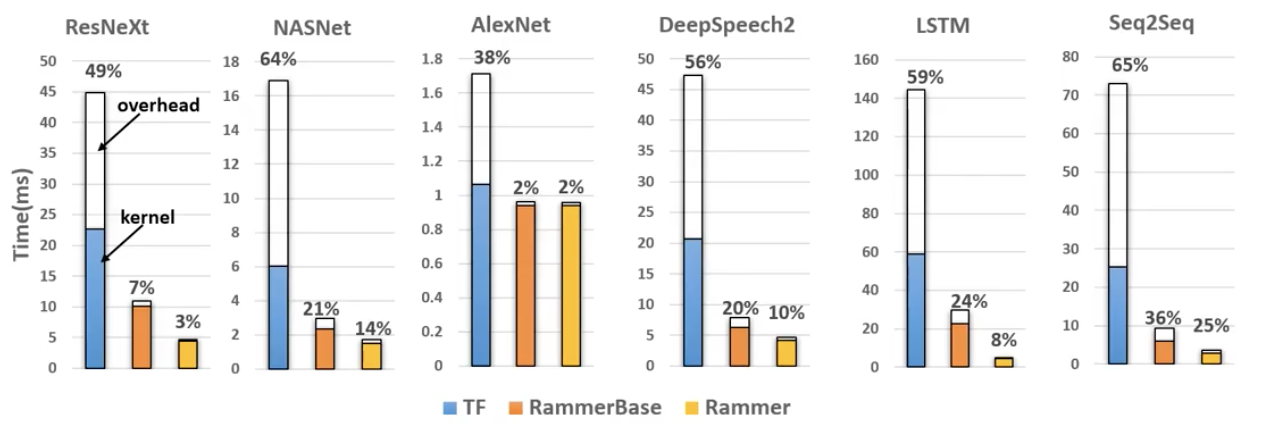
Rammer可以减少调度时间。但是没有评估Rammer导致的compile time的增加。
原文作者:Lingxiao Ma∗, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenxiang Hu, Fan Yang, Lintao Zhang, Lidong Zhou
原文链接:https://www.usenix.org/system/files/osdi20-ma.pdf
项目代码:https://github.com/microsoft/nnfusion
参考文献:[1] OSDI 2020 | 微软亚洲研究院论文一览 https://mp.weixin.qq.com/s/vHeXvAeEPPiTls349yjkAQ