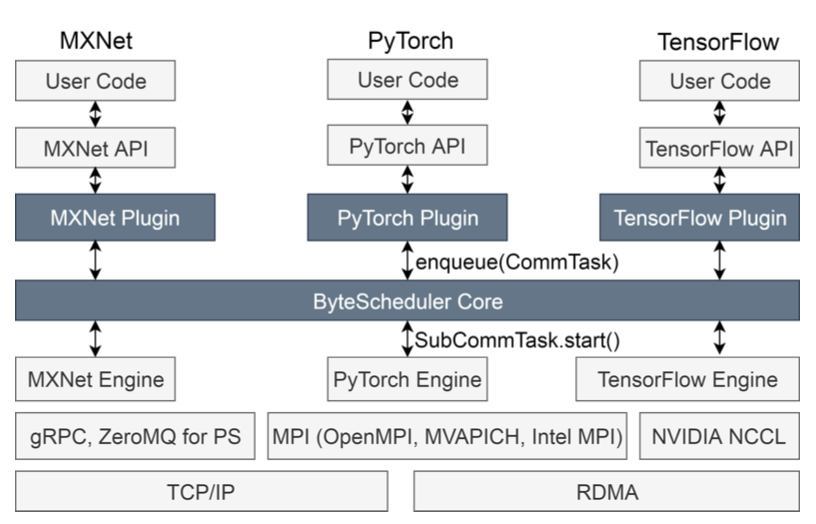
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
本文介绍了PyTorch DDP模块的设计、实现和评估。提供一个通用的数据并行训练package有三方面考验:
- 数学上的等价:需要保证和本地训练一样的训练收益
- 无需大量修改用户代码的以及截获性的API:方便用户运行数据并行训练,也要允许用户自定义通信和优化
- 高效:较高的训练吞吐量
背景
训练DNN模型的三步:
- Forward pass: 计算损失
- Backward pass: 计算梯度
- Optimizer step: 更新参数
PyTorch DDP采用all-reduce通信。All-recude是一种同步的通信机制,因为all-reduce只有在所有进程都准备好之后才能开始通信。与之相反,PS中采用的是P2P的通信方式。
系统设计
梯度Reduction
在过去的版本中,梯度Reduction的计算方法一直在不断改进。
Naive solution:DDP控制所有的训练进程(1)从同一个模型状态开始训练;(2)在每个iteration用同样的梯度。
通过在每次local backward之后梯度同步,或者加hook就可以实现(2),但是有两个performance上的问题:
小tensor中collective communication效率非常低
把梯度计算和同步分开之后,就不能把它们overlap了Gradient bucketing:Collective communications在大tensor上通信效率更高。因此,可以通过gradient reduction将几个梯度打包成一个allreduce操作。然而,为了让通信和计算overlap,DDP不能把所有的梯度都打包到一个allreduce里。
计算和通信overlap:在bucketing中,DDP只需要等一个bucket中的所有数据都准备好通信。需要注意(1)在所有进程中reduce的顺序一定要相同;(2)有时不同进程里backward中gradient计算顺序不同,或有的gradient被跳过,此时会导致hang。
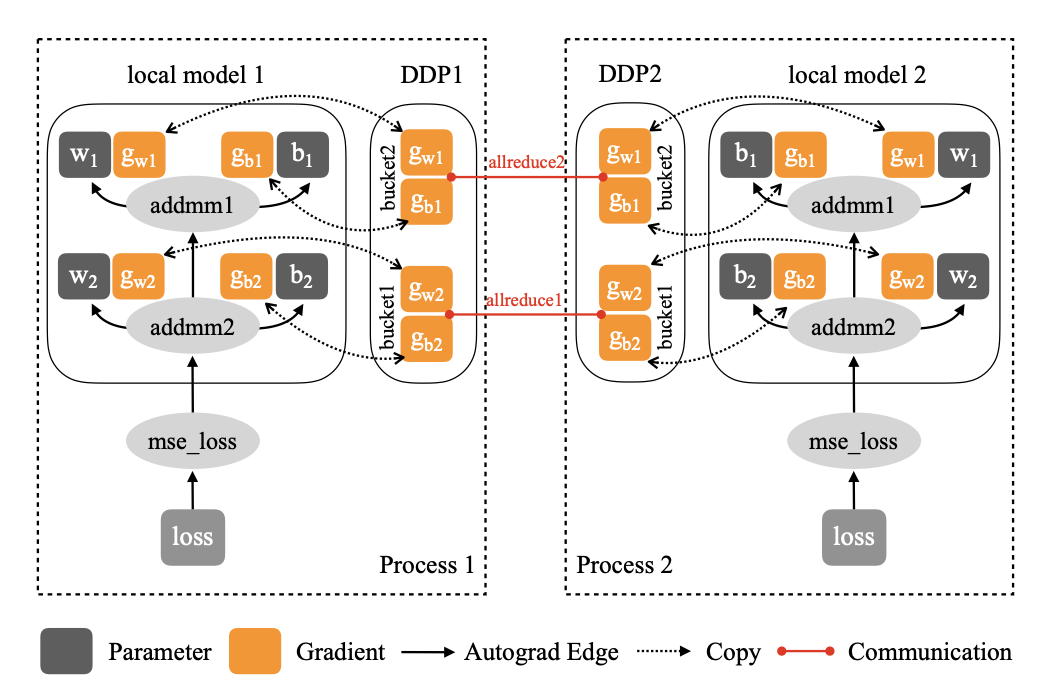
- 梯度累积:每n个iteration进行一次allreduce。
Collective Communication
DDP建立在NCCL、Gloo和MPI等通信库之上,把通信库里的API打包到ProcessGroup API中。在DDP里,worker需要加入通信组才能进行相关通信。
实现
- Python前端:有很多可以configure的节点,例如process group等等;支持单机多卡的模型并行;支持模型buffer,rank 0负责存储buffer的内容,在forward前将rank 0上buffer的内容broadcast到其他设备上。
- 核心梯度reduction:确保同一bucket中的parameter都来自同一个device;通过一个count来判断当前backward到了第几层,从而在合适的时候allreduce;默认bucket size为25M;在CPU上创建位图来保存本地没有使用的参数信息,并通过一个额外的allreduce得到global bitmap。
实验评估
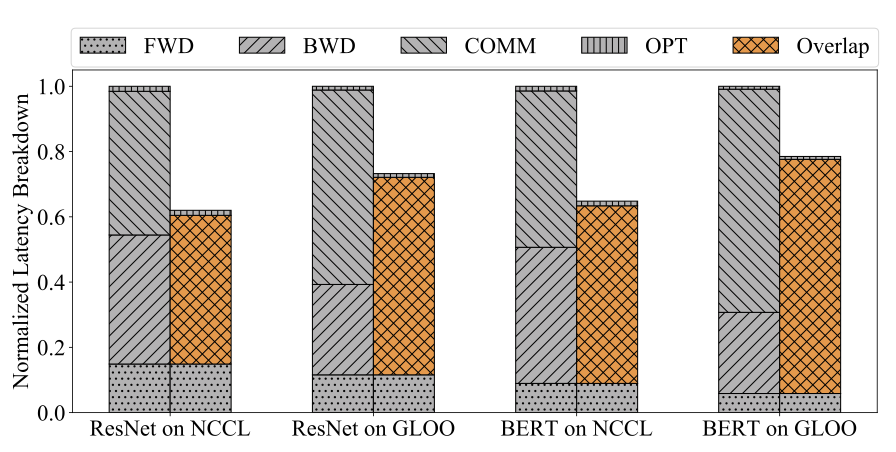
- 比较了不同模型、使用不同backend、有无通信和训练的overlap,并将latency breakdown为不同的部分来分析。
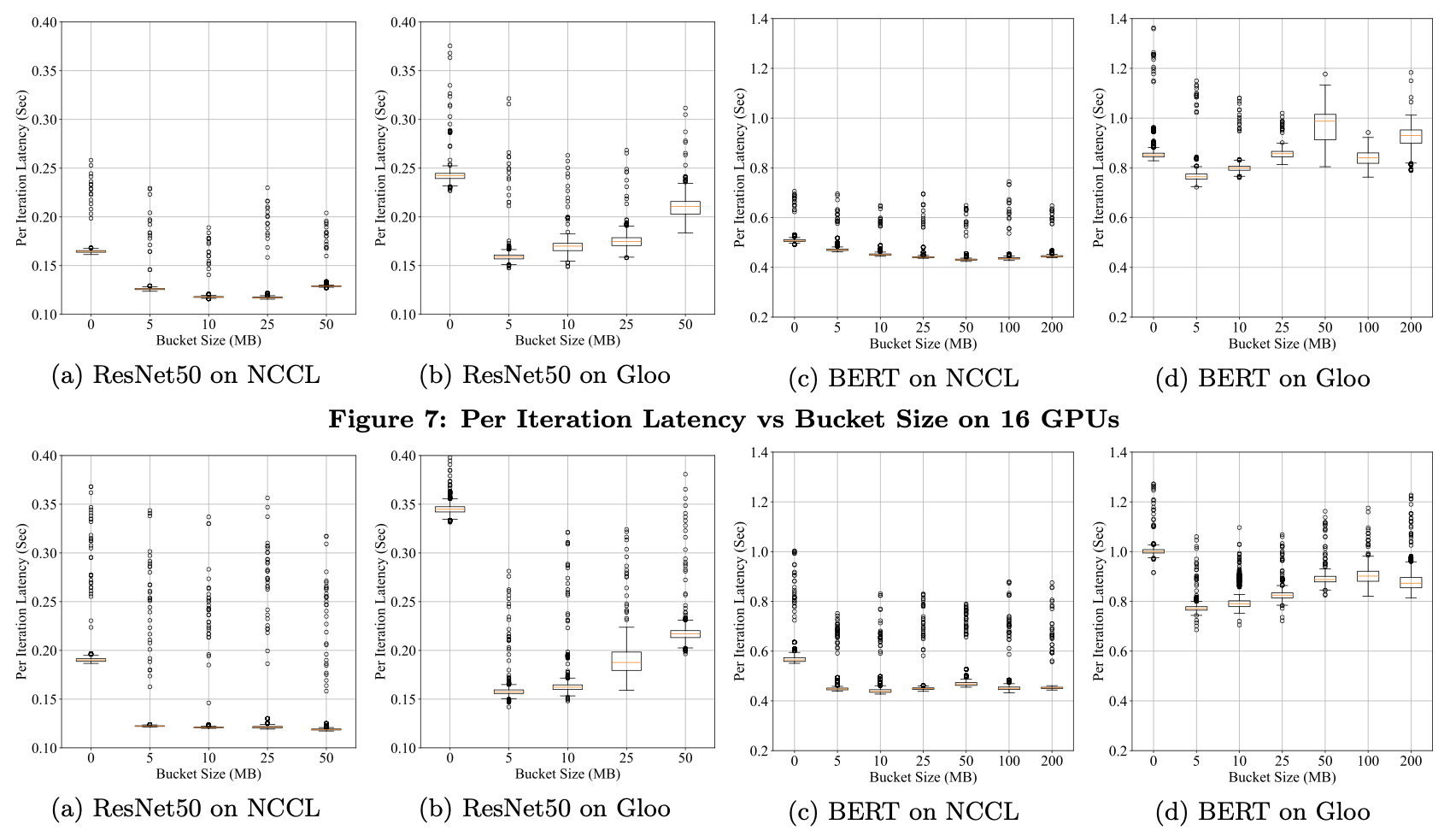
- 比较了不同的bucket size的影响。
比较了使用不同数量GPU时的latency、不同同步步调的latency以及loss。
DDP通过使用多个round-robin(轮询调度)进程组从而充分利用带宽。实验比较了使用不同数量进程组对latency的影响。
讨论
没有适用于所有情况的configuration,但是可以总结出一些规则来帮助找到最佳configuration:
通信backend:多数情况下,NCCL比Gloo快
Bucket size:随着模型的增大而增大
Resource allocation:用NCCL时,建议把所有的worker都放到同一台机器上的同一个进程组中
未来优化方向:
梯度顺序预测:使用自动梯度计算hook记录backward的order,并相应地向bucket mapping中更新参数
Layer dropping:在forward的过程中随机drop掉几层(加速训练,避免过拟合);与此同时相应修改parameter-to-bucket mapping,或从bucket level drop
梯度压缩: 只通信需要高精度的梯度
原文作者:Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, Soumith Chintala†
原文链接:https://arxiv.org/pdf/2006.15704.pdf
项目代码:https://github.com/pytorch/pytorch
参考文献:[1] PyTorch Distributed: Experiences on Accelerating Data Parallel Training https://ruipeterpan.gitbook.io/paper-reading-notes/machine-learning-systems/index/pytorch-distributed-experiences-on-accelerating-data-parallel-training