PipeSwitch: Fast Pipelined Context Switching for Deep Learning Applications
深度学习(DL)任务包括需要高通量的训练任务和需要低延迟的推理任务。目前的主流做法是提供专门的GPU集群,分别用于训练和推理。由于需要满足严格的服务级别目标(SLO),GPU群集通常会根据峰值负载过度配置,而不同任务类型之间以及应用程序之间对GPU的共享有一定的限制。本文提出了一个PipeSwitch系统,它可以使一个推理程序的未使用周期由训练或其他推理应用程序填充。它允许多个DL应用程序与整个GPU内存共享同一个GPU,并只增加毫秒级的切换开销。使用PipeSwitch,GPU利用率可以显著提高,且不会牺牲SLO。本文通过引入流水线式的上下文切换来实现这一点。其核心思想是利用神经网络模型的层级结构及其逐层计算的模式,在PCIe上进行流水线模型传输,并在GPU中以模型感知分组的方式执行任务。本文还设计了统一的内存管理和Active-Standby Worker切换机制,以配合上下文切换的流水线并确保进程间的隔离。
简介
深度学习任务包括需要高通量的训练任务和需要低延迟的推理任务。目前的主流做法是提供专门的GPU集群,分别用于训练和推理。推理集群常常参考峰值负载而分配过多的资源,以满足严格的服务级别目标(SLO)。即使对于推理任务本身,在实际应用中,通常按每个GPU的粒度将资源分配到每个程序,以减少应用程序之间的干扰。
理想情况下,多个深度学习应用程序应该能够打包到同一个GPU服务器上,以便通过时间共享实现GPU利用率的最大化。这正是操作系统如何通过任务调度和文本转换来提高CPU利用率的。但是和CPU不同,GPU在任务之间切换时有很高的开销。为了避免这种交换开销,现有的解决方案是在空间上共享GPU内存。
然而,现有的多任务系统支持例如Nvidia MPS远谈不上高效(切换时间甚至达几秒,而很多推理任务的SLO可能是毫秒量级)。但这样的系统对于调度是有重要作用的。考虑这样一个场景:将训练和推理任务混合部署在同一个集群里。训练任务一般是时间较长,SLO不敏感;推理任务则是对SLO相当敏感,且可能具备明显的潮汐特性(例如一些在线推理到了晚上workload会比白天轻一些)。这两类任务的差异还是很显著的,因此很多公司倾向于将它们各自部署在单独的集群中,但就会导致资源利用率问题,比如训练任务无法在晚上利用推理集群空闲出来的GPU资源。如果我们既想要将训练和推理混合部署,同时又希望它们之间的切换能够高效呢?这就是PipeSwitch希望解决的问题。
系统概览
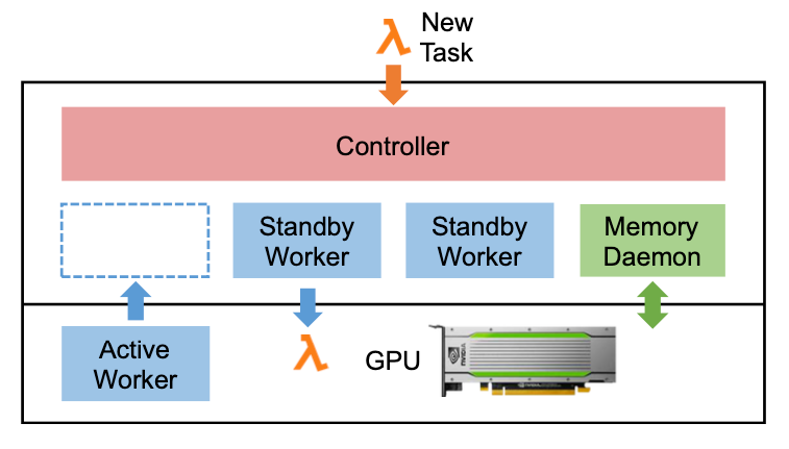
图1展示了PipeSwitch服务器的架构,包括四种不同的构件:
- 控制器。控制器是中心部件。它从客户端接收任务,并控制内存守护进程和工作进程来执行任务。
- Memory Daemon。Memory Daemon管理GPU内存和DNN模型。它将GPU内存分配给活动工作线程,并将模型从主机内存传输到GPU内存。
- Active Worker。Active Worker是当前在GPU中执行任务的worker。这里的worker指的是在一个GPU上执行任务的进程。
- Standby Worker。服务器有一个或多个Standby Worker。Standby Worker处于空闲状态,正在初始化新任务,或者正在为上一个任务清理其环境
如果要启动一个新任务,控制器要么等待当前任务完成(例如推理任务),要么通过通知Active Worker停止(例如训练任务)来抢占它。同时,控制器通知空闲的Standby Worker为新任务初始化其环境。在Active Worker完成或停止当前任务后,控制器通知Memory Daemon和Standby Worker将任务加载到GPU,以通过流水线式的模型传输执行。Memory Daemon将内存分配给Standby Worker,并将新任务使用的模型从主存传输到GPU内存。Standby Worker将成为新的Active Worker来执行新任务,而原来的ActiveWorker将成为Standby Worker并为上一个任务清理环境。本文的主要目标是根据深度学习应用程序的特点设计一种方法,以最小化该过程中的任务切换开销。
系统设计
流水线式的模型传输
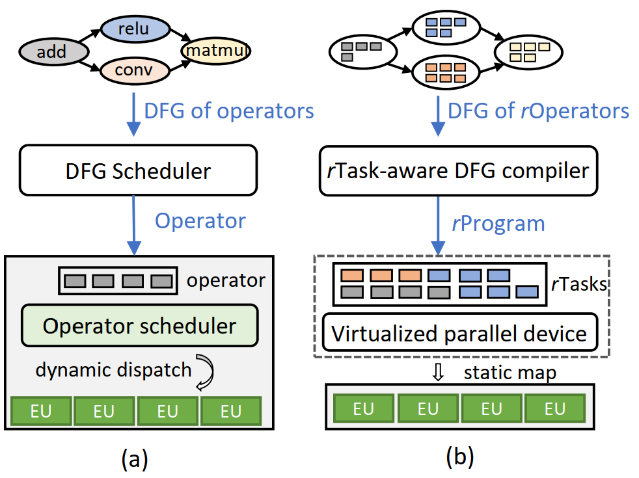
PipeSwitch利用了深度学习任务一个非常重要的特——DNN模型通常都包含多个layer,且计算都是按layer的顺序进行的,最前面的layer会在前向传播时首先被用到。所以在做context switch的时候,可以优先将靠前的layer所需要的状态信息加载进GPU中,同时GPU就先计算这些已经ready的layer,整个过程被流水线化了(如下图b所示)。而现有做法(图a)则是将整个DNN作为一个大黑盒,将它无脑地完整加载到GPU之后,再按layer进行计算。相比之下,显然PipeSwitch这种思路高效得多。
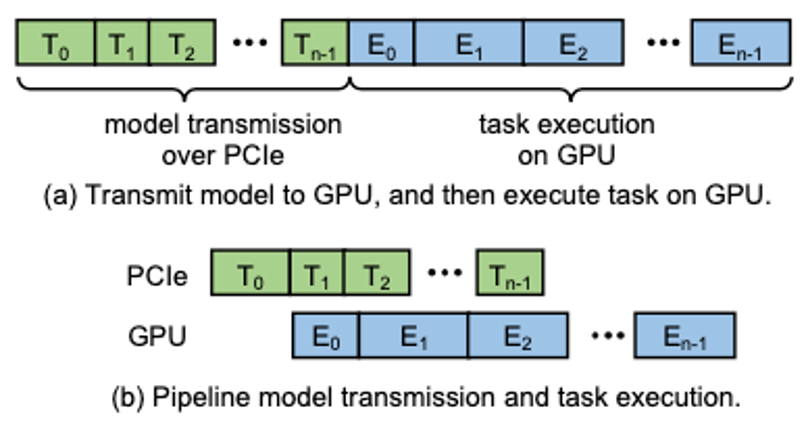
但是这样做存在两个问题,一个是多次调用PCIe传输数据开销较大;另一个是每次数据传输后都要进行数据同步,开销较大。本文的做法是grouping:将几个layer的数据组合成一个group来进行传输。
统一内存管理
PipeSwitch利用深度学习应用程序的两个特性来最小化GPU内存管理开销。深度学习任务在GPU内存中存储两种重要的数据:DNN模型(包括模型参数)和中间结果。首先,分配给DNN模型的内存量是固定的,并且在任务执行期间不会改变。并且存储参数所需的内存量保持不变。第二,中间结果以简单、规则的模式进行变化,这不会导致内存碎片。对于推理任务,中间结果是每层的输出,下一层使用这些输出。在计算下一层之后,就不再需要它们了,可以安全地释放它们。训练任务的不同之处在于,在前向传球中生成的中间结果不能立即释放,因为它们也被backward用来更新权重。然而,backward以与forward相反的顺序消耗中间结果,即中间结果是先进后出。内存分配和释放可以通过一个简单的堆栈式机制来处理,而不会造成内存碎片。一般的任务管理方式不考虑这些特点,且对于快速的上下文切换来说不够轻量级。
减少内存分配开销。PipeSwitch使用一个内存守护进程来管理GPU内存。为了与现有系统兼容并进行最小的更改,内存守护程序在系统启动时使用cudaMaloc来获取GPU内存,然后在运行时将内存动态分配给工作线程,而不是替换GPU内存管理器。这消除了每个工作人员使用cudaMaloc获取大量内存来存储其模型和中间结果的开销。内存守护进程只需要将内存指针传递给worker,这是轻量级的。守护进程确保每次只有一个worker拥有GPU内存,以保证工作进程之间的内存隔离。每个工作线程使用内存池分配内存以存储其模型和中间结果,并在不再需要中间结果后将内存回收到池中。
最小化内存占用并避免额外的内存拷贝。PipeSwitch将模型存储在内存守护进程中,这样服务器只需要在主存中保留每个模型的一个副本。因为内存守护进程还管理GPU内存,所以它直接将模型从主存传输到GPU内存以进行任务启动,这就消除了从内存守护进程到worker的额外内存拷贝。
最小化IPC开销。神经网络模型的内存分配过程是确定性的。具体地说,给定相同的GPU内存区域和相同的模型,只要内存守护进程和worker使用相同的顺序为模型参数分配内存,那么参数的内存指针将是相同的。内存守护进程和worker很容易保持相同的顺序,因为神经网络模型是已知的,并且内存守护进程只需要使用与worker相同的顺序来传输模型。内存守护进程只使用一次GPU IPC初始化worker,然后使用廉价的CPU IPC通知worker哪个管道组已经被传输,这样可以将昂贵的GPU IPC的使用降至最低。
Active-Standby Worker之间的切换
本文设计的一个Active-Standby Worker切换机制,隐藏了任务清理和任务初始化的开销:
每个worker都是一个独立的进程,并且在第一次创建它时初始化它自己的GPU环境(即CUDA上下文)。这消除了将新任务分配给工作线程时的GPU环境初始化开销。PipeSwitch将“同步点”插入到训练任务中,这样排队中函数的数量是有限的,并且可以快速清除GPU上排队的异步CUDA函数。而推理任务不需要同步点,因为推理任务可以很快完成且不被抢占。另一个任务是释放GPU内存。PipeSwitch的清除过程的一个重要特性是它不修改内存的内容,而只清理元数据,即GPU内存指针。由于GPU内存由PipeSwitch管理,清理过程只删除指向张量数据的指针,而不是释放实际数据。因此,新任务将其模型同时传输到GPU内存是安全的。也就是说,我们可以将当前任务的任务清理和新任务的流水线模型传输并行化,以隐藏任务清理的开销。
实验评估
作者首先使用end-to-end实验来证明PipeSwitch带来的效果,然后通过实验说明每个组件的设计的有效性。最终效果是PipeSwitch能够实现不超34.6ms的额外切换开销(远低于Nvidia MPS)。

总结
本文提出了PipeSwitch,一个能够为多个深度学习应用程序实现GPU高效细粒度分时的系统。PipeSwitch通过流水线式上下文切换来最小化深度应用程序GPU上的任务切换开销。流水线上下文交换包括三个关键技术:流水线式模型传输、统一内存管理和Active-Standby Worker切换。通过这些技术,PipeSwitch能够实现毫秒级的任务切换时间,使分时GPU上的深度应用程序能够满足严格的SLO。本文在各种DNN模型和GPU上进行了实验,验证了PipeSwitch的性能。PipeSwitch可以显著提高GPU的利用率,提高深度应用的灵活性。其实这种流水线的思路其实在去年SOSP上出现的PipeDream和ByteScheduler中也都有体现,也可以应用于与深度学习任务相关的其他方面的系统级优化。
原文作者:Zhihao Bai, Zhen Zhang, Yibo Zhu, Xin Jin
原文链接:https://www.usenix.org/system/files/osdi20-bai.pdf
项目代码:https://github.com/netx-repo/PipeSwitch
参考文献:[1] OSDI 2020 有哪些值得关注的文章?https://www.zhihu.com/question/414538410/answer/1550912187