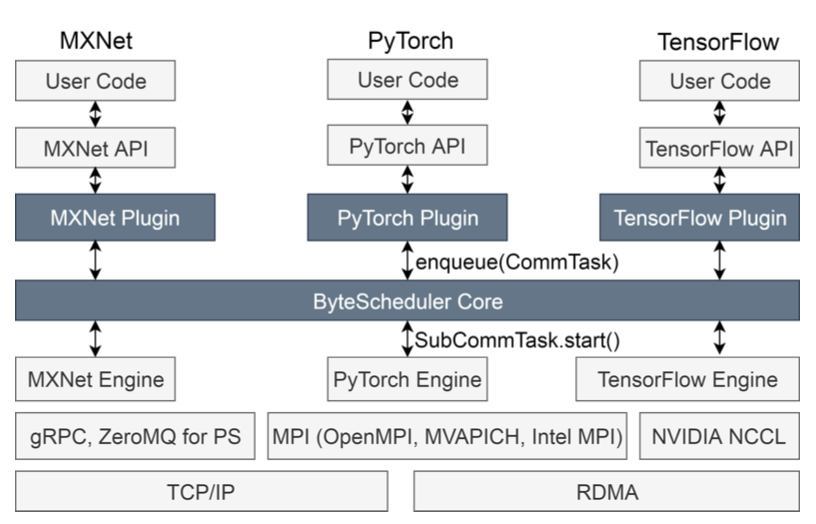
BPIPE: Memory-Balanced Pipeline Parallelism for Training Large Language Models
背景
流水线并行为每个GPU分配一个单独的流水线阶段(stage),用于计算模型中的不同层。因此,每个流水线阶段都具有对其他阶段的数据依赖性,并导致计算暂停直到所需的数据到达,通常称为“流水线气泡”(bubble)。为了最大限度地减少气泡,1F1B(一个正向和一个反向)流水线将输入micro-batch,并交替处理正向计算和反向计算。为了使所有流水线阶段饱和,早期阶段比后期阶段保留更多的内存用于计算更多的前向微批。因此,流水线阶段之间存在内存不平衡,如果早期阶段内存不足,则执行模型失败,如图1所示。
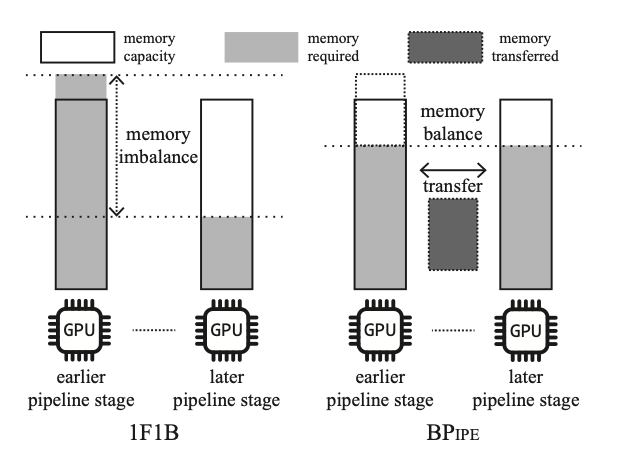
作者观察到,后期阶段无法使用与早期阶段相同大小的GPU内存来预计算前向micro batch。因此,如果我们能够利用后期的空闲内存作为前期的额外内存,那么均衡的内存负载将缓解内存压力。此外,降低的内存压力能够利用更多的内存来加速训练,避免冗余的重新计算、增加微批量大小或降低模型并行度。
方法
激活值平衡

在具有m个微批次的p路流水线并行中,用A(s)表示第s个阶段最多存储的激活值的内存量,W(s)为包括优化器状态在内的模型参数大小,则第s个阶段的内存使用量M(s) = A(s) + W(s)。假如没有一个阶段的模型层数相同,则W(s)为一个恒定的值W_0。μ(s)为第s个阶段最多能保存的微批次数量,A(s) = A0μ(s),M(s) = W0 + A0μ(s)。
根据图2,1F1B流水线中的每一个阶段最多通信μ(s) = min(p − s, m)次。实际上,为了让所有流水线的阶段饱和,m远大于p。因此,μ(s) = p − s。
作者将阶段s和阶段p−s−1配对,每一对中的内存不均衡可以被写为:M(s) − M(p − s − 1) = A_0(p − 2s − 1)。

传输调度
为了达到内存均衡的目标,不同阶段之间数据的传输需要调度,调度算法决定何时传输或者加载什么数据。算法的核心思想是:(1)保证μ(s)不超过优化的最优值;(2)反向传播计算需要某个激活值,但是该激活值不在相应的GPU上的时候,去其配对的GPU上加载激活值;(3)如果某次激活值的加载会使得μ(s)超过优化的最优值,则算法会提前传输出去一个激活值,以此预留出足够的内存。
“阶段对”的GPU分配
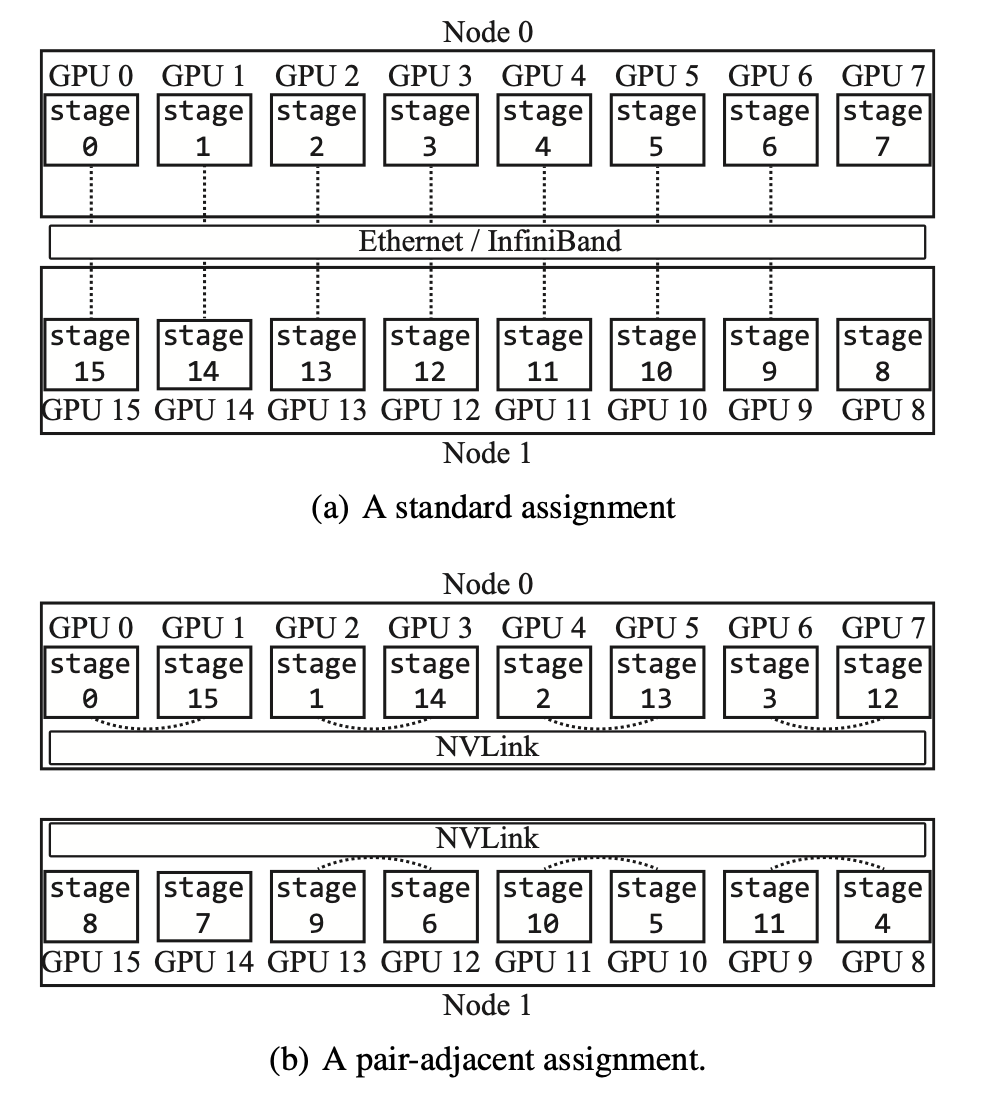
如图4所示,BPipe把配对的一对GPU分配在相邻的位置,这样可以减小激活值传输的时间,从而让激活值传输的时间被计算的时间完全overlap,从而减小BPipe内存优化对计算性能的影响。这样虽然会让训练时不同stage之间的通信变慢,但是内存平衡的通信时间比训练时不同stage数据依赖的通信量更大。
实验评估
作者通过分别的CUDA stream进行激活值的传输和加载,为激活值手动管理CUDA内存。作者在6台具有8个A100 GPU的服务器上进行了实验,实验中训练了GPT-3模型。
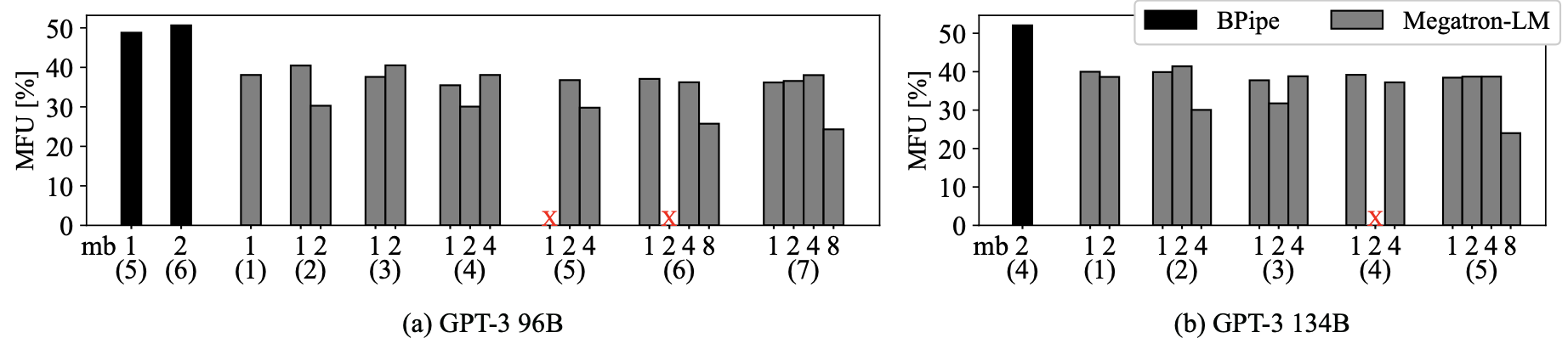
实验结果表明,BPipe按照Megatron-LM无法执行的配置进行GPT-3的训练,比Megatron-LM执行最快的配置快1.25倍。
总结
本文提出了BPipe,通过在流水线阶段之间传输中间激活的激活平衡,BPIPE解决了流水线并行的内存不平衡问题。实验评估表明,BPipe通过执行更快的训练配置来加快大规模GPT-3模型的训练,并且如果没有BPipe,这样的配置无法运行起来。
原文作者:Taebum Kim, Hyoungjoo Kim, Gyeong-In Yu, Byung-Gon Chun
原文链接:https://openreview.net/pdf?id=HVKmLi1iR4