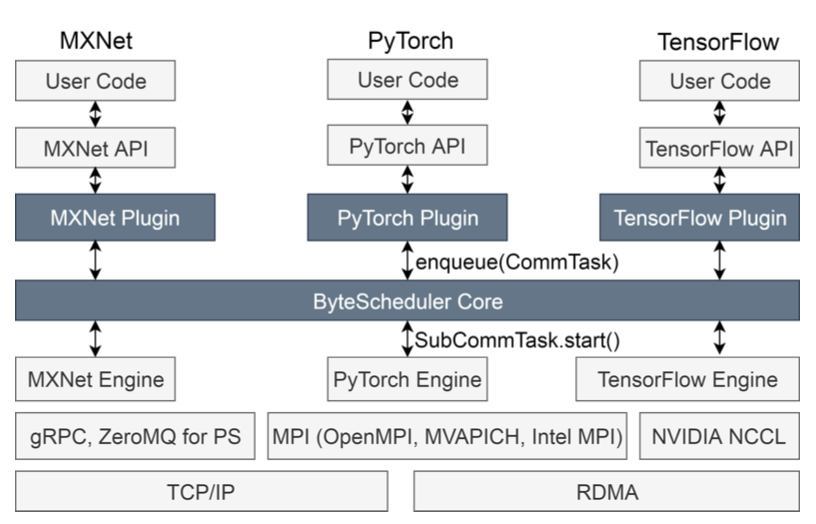
A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters
本文是字节跳动、清华大学和Google合作的项目,提出一种分布式DNN训练的统一架构BytePS,并延续了字节跳动在RDMA方面的研究,利用了RDMA高速网络的特性对集群的通信和算力资源利用率进行优化。
背景和动机
即使目前已经有了许多,数据并行的效率远远没有达到理想的情况。
本文希望解决的三个问题:
- 多机之间通信并不充分
- 单机内部GPU之间的通信也有瓶颈
- CPU的性能限制了训练的效率
通过从字节跳动异构集群中收集的3个月的trace,可以看出:(1)CPU并没有被很好的利用;(2)很多服务器运行的是非分布式任务,这些机器的贷款并没有被很好的利用。这提供了一个很好的机会:异构集群中有剩余的CPU和带宽。本文的设计目标是去充分利用这些没有被利用起来的资源。

设计
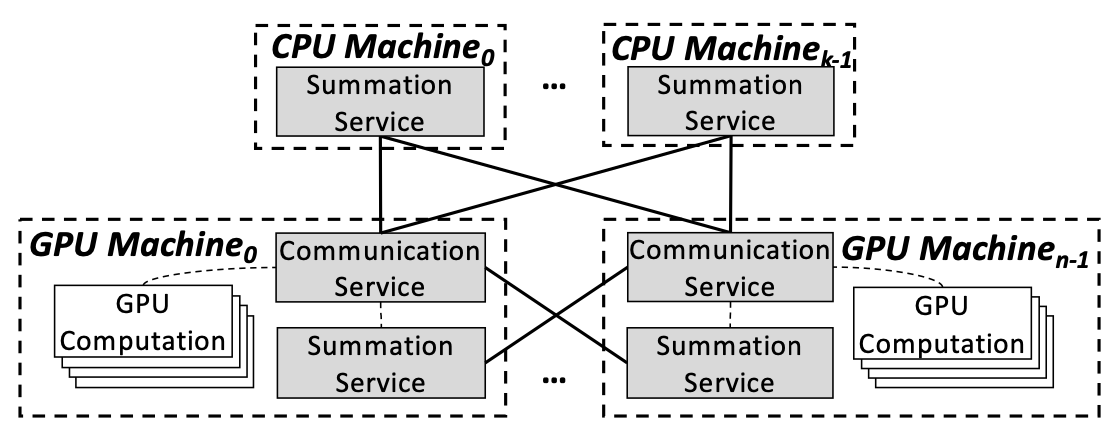
多机之间的通信
一方面,PS只利用GPU和CPU之间的带宽进行通信。如果CPU服务器的数量不充足,那么GPU服务器的带宽就没有被充分利用。另一方面,all-reduce只利用GPU服务器之间的连接,CPU服务器的带宽完全没有被利用。所以最好的策略是把二者结合起来,这样所有机器之间的连接都能被利用,并且能充分利用CPU资源。这带来一个问题:如何分割这些link workload?
用x和y分别代表CPU-GPU traffic所占百分比和GPU-GPU traffic所占百分比。可以计算出最佳的策略下x和y的值。其中,n和k分别是GPU和CPU服务器的数量。在理论上,这样的partition策略可以达到最短的通信时间。
$$
x = \frac{2k(n - 1)} {n^2+kn-2k}, y = \frac{n(n - k)} {n^2+kn-2k}
$$
单机内部的通信
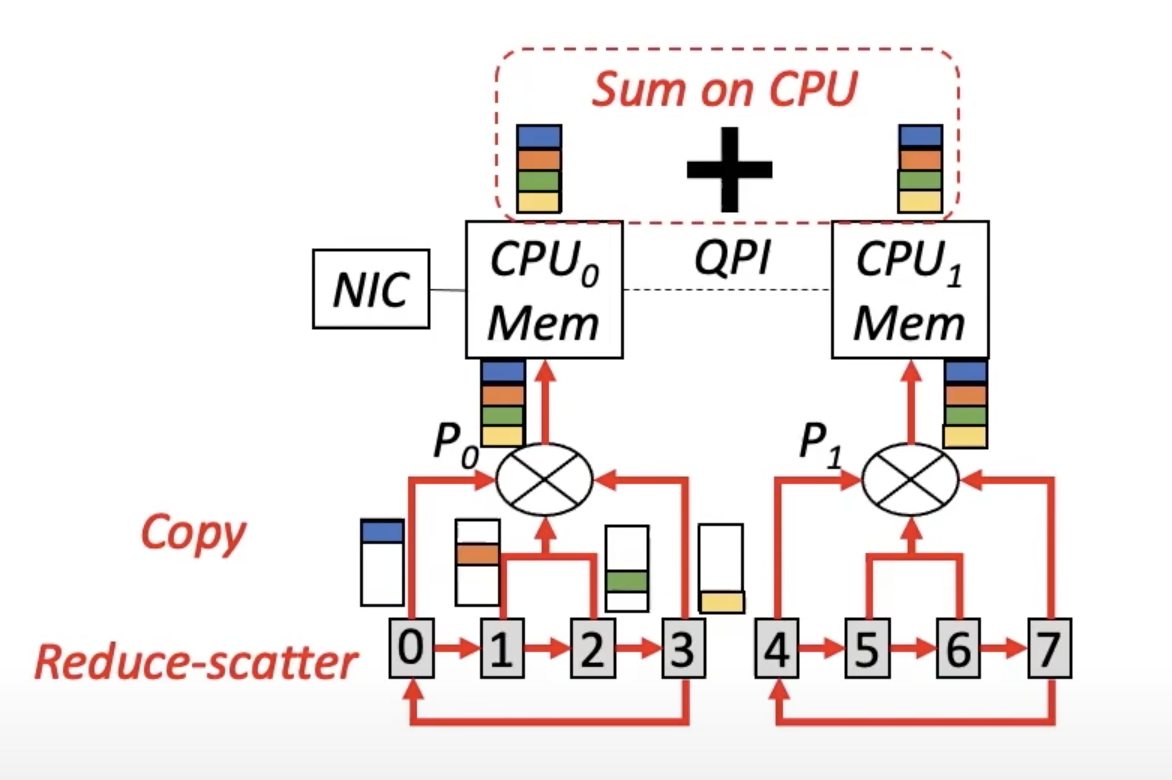
如图所示,当单机之间只有PCIe拓扑结构时,瓶颈在于CPU和PCIe switch之间的连接。本文希望能够尽可能减少这个连接之间通信。然而,像MPI或者NCCL等通信库直接对这8个GPU做all reduce。根据all-reduce算法可以计算出,直接做all reduce时,bottleneck link上有7M/4的通信量,M是每个GPU上的模型大小。这个通信量对于bottleneck link来说太大了。
BytePS通过CPU-assisted aggregation的方法来解决这个问题。首先,在同一个PCIe switch下的四个GPU之间进行一次local reduce-scatter。这样每块GPU上有1/4的aggregated gradient。然后每个GPU把它所拥有的四分之一copy到主存中。最后,CPU把两个PCIe switch下的gradient加和。现在在bottleneck link上的通信量只有M。理论上该方法比MPI/NCCL快24%。
对于有NVlink的GPU machine,可以用类似的方法分析瓶颈所在的连接,并设计方法减少瓶颈连接上的通信量。
对于不同的拓扑结构来说,最优的通信算法不同,并不存在一个对所有拓扑结构都适用的算法。
解决CPU瓶颈
现象:optimization可以分成两个阶段:梯度加和和参数更新。前者对CPU友好,后者对于CPU来说计算量过大。
parameter server把forward和backward放在GPU上,把整个optimization放在CPU上。本文提出Summation Service:把optimization中的参数更新放到GPU上计算。

但是这样是否会有过多的context switch从而带来这方面的overhead,作者没有讨论。
实验评估
多种模型、框架、baseline。
多机之间通信:byteps的通信表现可以达到几乎最优;CPU服务器越多,BytePS的表现越好。
单机内部通信:对于有PCIe和NVlink的机器,都有很大的performance提升。
End-to end scalability:在各种情况下的throughput都有所提升,GPU数量越多,提升越大。
原文作者:Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo
原文链接:https://www.usenix.org/system/files/osdi20-jiang.pdf
项目代码:https://github.com/alibaba/GPU-scheduler-for-deep-learning