Is Network the Bottleneck of Distributed Training?
近期有许多工作致力于提高分布式训练的通信效率,但是很少有工作致力于系统地研究网络是否是瓶颈、以及网络在多大程度上限制了分布式训练的效率。在这篇文章中,作者度量并分析了分布式训练的网络表现。作者预期,度量结果会证实通信是阻碍分布式训练达到linear scale-out效果的原因。但是,作者发现实际上网络带宽利用率很低,如果网络带宽可以被充分利用,分布式训练的scaling factor可以接近于1。
另外,目前很多人提出压缩率超过了100的梯度压缩方法,作者发现在充分利用起来带宽的情况下,在100Gbps带宽下没有梯度压缩的必要。另一方面,10Gbps的低带宽下仅需要2-5倍的梯度压缩率就可以达到接近linear layout的效果。和梯度压缩这种应用层级的方法相比,网络层级的优化不需要对应用作出改变也不会有模型表现的损失。因此,作者提倡对分布式的网络社区做出真正的改变,以充分利用网络能力,达到linear scale-out。
本文由约翰斯·霍普金斯大学金鑫老师的团队发表于SIGCOMM’20,目前金鑫老师已就职于北京大学软件工程研究所。
简介
DNN模型越来越大,越来越深。然而,与快速增长的DNN模型需求相比,单芯片提供的计算能力仍然有限。因此,训练大型DNN模型不可避免地通过扩展(scale out)得到越来越多的分布。横向扩展的最优目标都是线性扩展(linear scalability)。也就是说,假设单个设备的吞吐量是T,那么具有n个设备的系统的吞吐量应该是nT。让具有n个设备的系统实际实现的吞吐量为Tn。我们将scaling factor定义为:
$$
scaling factor = \frac{T_{n}} {nT}
$$
线性扩展要求任何n的比例因子都为1。
人们普遍认为,网络带宽是阻碍分布式训练提前扩展的瓶颈。因为计算阶段是并行的,因为每个线程都独立地处理自己的batch,所以n个worker的吞吐量是一个worker的n倍,因此只有通信阶段才能减慢训练过程。针对这一点,最近几年,机器学习和系统界对提高分布式训练的通信效率进行了大量的研究。这些工作主要在应用层完成,且假设网络已经尽了最大的通信效率。然而,很少有工作系统地理解网络是否是瓶颈以及在多大程度上是瓶颈。
本文首先分析了分布式训练的原理和方法:对几种具有代表性的DNN模型在AWS上的训练吞吐量进行了measurement study。实验结果证实了通信是阻止分布式训练线性扩展的因素。然而,作者发现,网络带宽其实并不是瓶颈,因为带宽的利用率很低。
基于记录结果,作者做了一个假设分析,在该分析中,作者控制网络带宽并对假设带宽被充分利用。分析结果表明,在充分利用网络的情况下,分布式训练可以达到99%以上的scaling factor。作者通过梯度压缩进一步扩展了假设分析。
本文的两个主要贡献点:
- 系统地测量和分析了分布式训练的性能瓶颈。与一般的观点相反,作者揭示了主要问题不在于网络速度,而在于通信阶段的软件实现问题。
- 进行假设分析,以评估高性能网络传输对分布式训练带来的好处。作者认为真正的挑战是网络社区为分布式训练开发高性能的网络传输,以充分利用网络容量并实现线性扩展。
记录训练的performance
Set Up
硬件:Amazon EC2 p3dn.24xlarge instances with 8 GPUs (NVIDIA Tesla V100)。
软件: Horovod 0.18.2, PyTorch 1.3.0, Torchvision 0.4.1, NCCL 2.4.8, cuDNN 6.6.0.64, and Open MPI 4.0.2. Horovod, NCCL, and Open MPI 采用 Linux kernel TCP通信。
WorkLoad:ResNet50、 ResNet101和 VGG16三种模型,ImageNet数据集。
当前的scaling factor
作者采用单个GPU上的吞吐量作为基准吞吐量T。实验中,改变服务器的数量。对于每种情况,测量服务器可以实现的总吞吐量,并计算scaling factor。
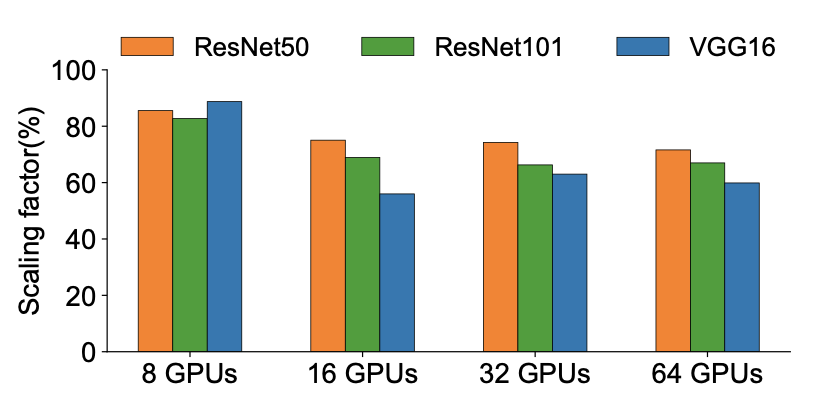
图1显示了不同服务器数量下每个模型的scaling factor。结果表明,ResNet50、ResNet101和VGG16的scaling factor分别为75.05%、68.92%和55.99%,4台服务器分别为74.24%、66.28%和63.01%,8台服务器分别为71.6%、66.99%和59.8%。ResNet50实现了比ResNet101和VGG16更好的scaling factor,因为ResNet50模型相对比较小,通信负担轻。然而,对于这三种模型,Horovod在AWS上无法达到超过76%的比例因子。
这些结果证实了目前像Horovod这样的现成的分布式训练框架不能实现linear scaling,且与linear scaling存在着很大的差距。
计算是瓶颈吗?
在计算部分,每个worker将一个batch的label好的图像输入神经网络模型,并局部计算梯度。如果一个worker完成一个batch的计算时间随着worker数量的增加而增加,那么计算就是分布式训练的瓶颈。
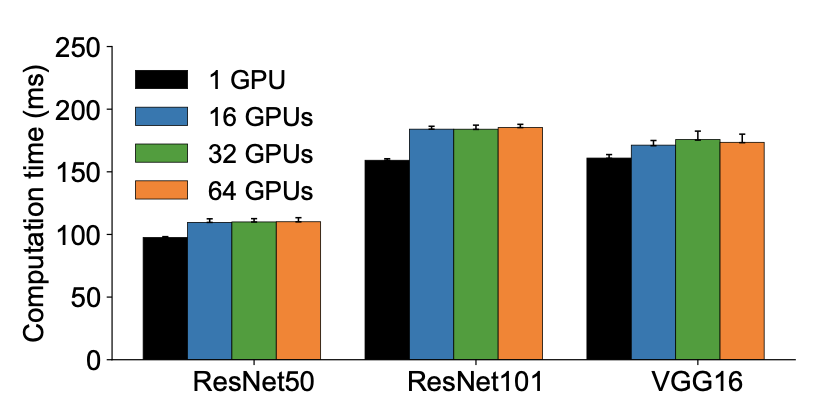
图2显示了具有不同worker数量的三个模型的计算时间(正向和反向传播)。可以看到计算时间几乎相同。单个GPU和多个GPU之间的时间差主要来自两个因素。首先,分布式训练中反向传递的运行时间不仅包括backward op,而且还包括所有的reduce操作,因为它们在GPU上是异步的,并且是重叠的。然而,对于单个GPU的情况,不存在所有的reduce操作。其次,Horovod在分布式训练过程中为模型中的每一层加了一个hook,这在单个GPU训练中是不存在的。然而,即使我们认为这些计算时间的gap是不可避免的,scaling factor仍应在90%左右,而不是测量出来的56%-75%,因为在分布式训练中测量的计算时间最多增加15%。因此,作者认为计算时间的gap不是分布式训练不能linear scaling的一个因素。
网络是瓶颈吗?
由于计算所花费的时间与服务器数量无关,因此唯一的可能性是通信组件是系统扩展时的瓶颈。为了验证这种情况,作者首先测量不同网络带宽下的scaling factor。如图3所示,ResNet50的scaling factor随着网络带宽的增加而增加。在两台服务器的情况下,当带宽从1 Gbps增加到10 Gbps时,扩展因子从13%增加到68%。这是可以理解的,因为带宽越高,worker之间交换相同数量的数据所需的时间就越短。基于all-reduce算法,由于要交换的数据更多,所以随着worker数量的增加,scaling factor会降低。

大家普遍认为网络太慢时发送梯度太慢从而限制训练效率。然而,与之相反的事,图3显示网络在25 Gbps后趋于稳定。这意味着系统不能从更快的网络中获益。为了验证这一点,作者通过记录实时网络吞吐量来测量服务器的网络利用率。图4表明,服务器确实在低带宽(例如1 Gbps)下充分利用网络,但在高带宽(例如100 Gbps)下,它们只使用很小一部分带宽。这意味着仅仅增加带宽以使网络更快,对于提高某一点后的sclaing factor是没有用的。
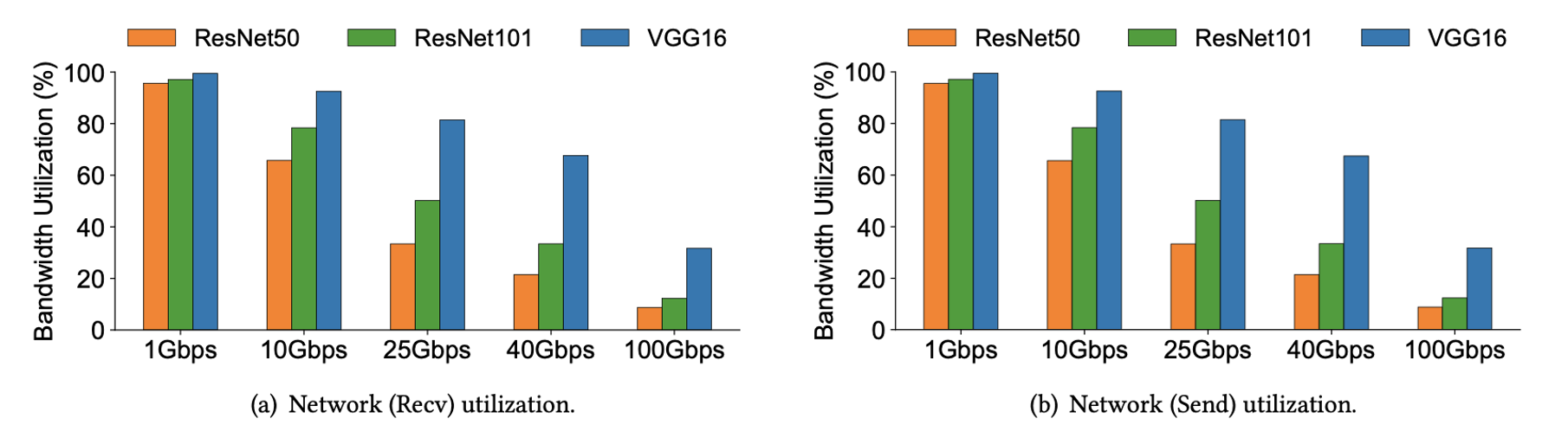
在高带宽下利用率低的一种可能性是CPU是瓶颈,因为实验在TCP上运行Horovod,而且以100Gbps这样的高速运行TCP是CPU密集型的。然而,分布式训练的计算大多是由GPU完成的,而且大多数GPU都配备了足够多的CPU。通过实验,作者发现在分布式训练时,CPU的利用率很低,因此CPU不是充分利用100Gbps网络带宽的瓶颈。
总之,实验结果证实了通信是瓶颈。但与普遍的看法不同,这并不是因为网络发送数据太慢。根本原因在于网络传输的实现不佳,导致不能充分利用可用带宽。
假设分析
如果带宽被充分利用,会发生什么?
作者首先分析,如果网络得到充分利用,可以达到什么样的scaling factor。为了进行假设分析,作者通过hook记录了模型不同层的梯度计算时间。
作者进行了两个模拟进程:对backward的模拟,和对all-reduce的模拟。两个进程通过一个message queue来通信。backward进程通过log记录的数据模拟backward计算。在某一层的backward计算完成后,它不会立刻向all-reduce进程发送请求,而是把几层的梯度放到buffer里,这里才用了Horovod fusion buffer的strategy。buffer满了或者time out之后才进行all reduce。数据传输的时间用(2S(N-1)/N)/bw来预估,S为all reduce size。向量相加的时间用(N-1)*AddEst(S/N)来预估,AddEst(x)通过在GPU上profile等方式预估。
overhead由 $t_overhead =t_sync −t_back$ 预估,scaling factor由 $f_sim =tbatch/(t_batch +t_overhead)$ 预估。
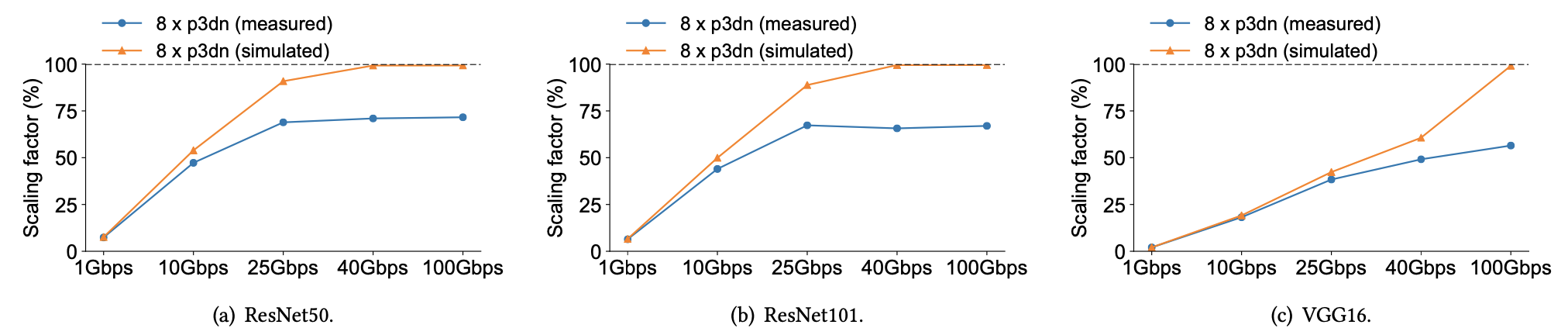
图5中模拟得到的scaling factor和实际测量得出的scaling factor的对比说明,网络在低带宽下得到了充分利用;在高带宽下(即在25 Gbps之后),两条线路开始明显偏离。
作者还使用假设分析来评估不同worker数量下的scaling factor。假设网络被充分利用,即使是64个GPU,这三个模型都可以达到接近100%的scaling factor。总的来说,假设分析证实了分布式训练可以从高网络带宽中获益,而且如果充分利用网络,scaling factor可以提高到接近100%。
应用层级优化有多有用?
在这个subsection的实验保持其他模拟步骤与之前提到的相同中相同,但将梯度传输的时间成本除以梯度压缩比。
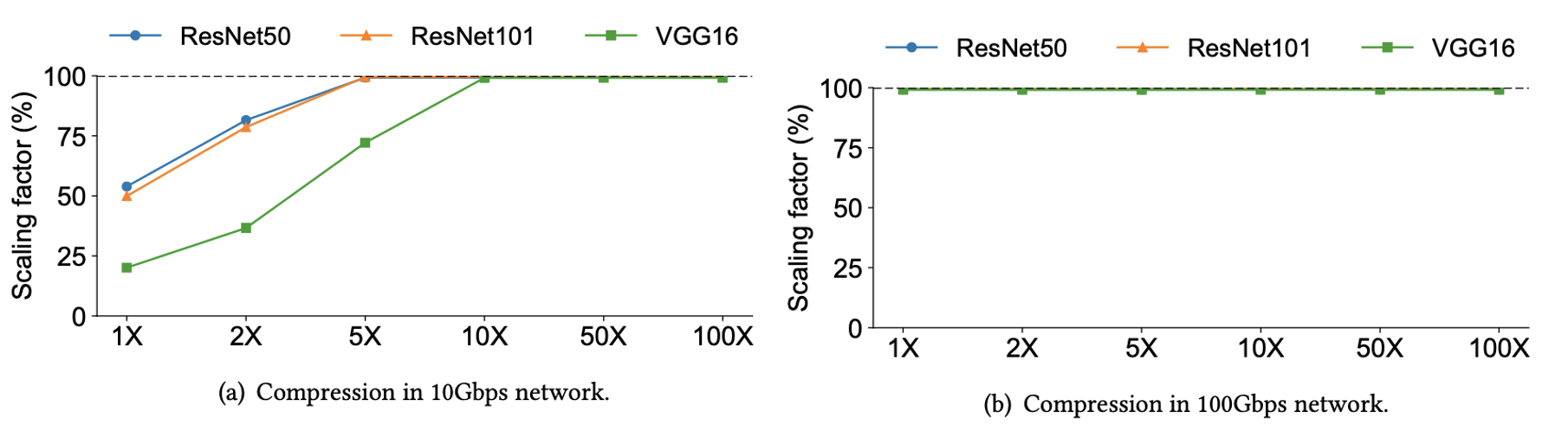
梯度压缩可能会降低向量加法的成本,从而进一步提高模拟得到的scaling factor。但是,如图所示,模拟的结果说明我们可能不需要像一些过去的工作中所说的那样需要高压缩比。对于VGG16这样的模型来说,10×的压缩比足够大,在10Gbps网络中可以获得接近100%的scaling factor。100 Gbps的结果也表明压缩在高速网络中没有多大用处。因此,梯度压缩技术在低速网络中是有用的,但是在现代网络环境中不需要有很大的压缩比。
讨论与未来工作
研究结果背后的基本原理 如果网络得到充分利用,scaling factor可以接近100%,这个发现是合理的。首先,很大的网络带宽下,传输ResNet50、ResNet101和VGG16的所有参数仅需7.8 ms、13.6 ms和42.2 ms。第二,在计算和通信之间有很大的overlap。最后一层的所有reduce可以在backward计算完最后一层的梯度后立即开始,而不必等待整个backward过程完成。所以,结合高效的通信和计算与通信的overlap,scaling factor可以达到接近100%
应用层优化的权衡 假设分析表明,应用层中的梯度压缩只在低网络带宽下笔比较有效。作者认为,它对云上的分布式训练或配备GPU或TPU的本地集群没有特别大的用处。
作者还认为,在如今的分布式训练中,网络带宽不是主要问题,主要问题在于网络传输是否有很好的实现。
原文作者:Zhen Zhang, Chaokun Chang, Haibin Lin, Yida Wang, Raman Arora, Xin Jin
原文链接:https://xinjin.github.io/files/NetAI20_Training.pdf