A Generic Communication Scheduler for Distributed DNN Training Acceleration
本文发表于SOSP’19,由香港大学和字节跳动合作,提出了一种用于分布式DNN训练加速的通用通信调度算法ByteScheduler。ByteScheduler的设计基于这样的原则性分析:对tensor传输进行划分和重新排列可以在理论上获得最佳结果,并且在实际应用中可以获得良好的性能,即使在有调度开销的情况下也是如此。为了使ByteScheduler能够在各种DNN训练框架中通用地工作,本文引入了一个统一的抽象和一个依赖代理机制来实现通信调度,且不破坏框架引擎中原有的依赖关系。在此基础上,本文提出了一种贝叶斯优化方法,可以在不同的网络环境下,根据不同的训练模型自动调整tensor划分的大小和其他参数。ByteScheduler现在支持TensorFlow、Pythorch和MXNet,无需修改它们的源代码就可以很好地与参数服务器(PS)和all-reduce架构(使用TCP或RDMA)进行梯度同步。实验结果表明,ByteScheduler在所有实验系统配置和DNN模型下的训练速度提高了196%(原始速度的2.96倍)。
研究背景和动机
深度神经网络(DNN)在计算机视觉、自然语言处理等各个领域都有十分广泛的应用。然而,由于训练数据集和DNN模型的大小都在逐渐增大,训练DNN的任务需要很长的时间和大量的计算资源。目前最常见的方式是通过数据并行加速DNN训练,但是由于通信的开销,其效果远不如“线性的加速”。
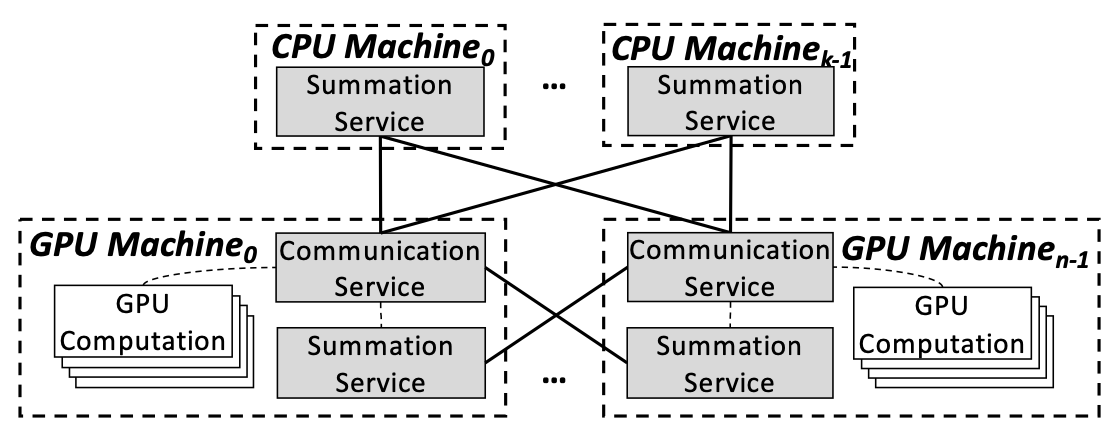
基于参数服务器(PS)的数据并行通信通常由三步组成:
- push:每个worker用本地的训练数据计算梯度并将梯度发送到PS;
- update:PS将各个worker的梯度加和并更新参数;
- pull:各个worker与PS进行参数同步。
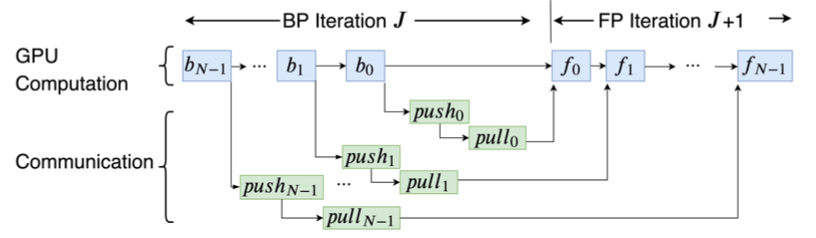
在DNN的分布式训练中,对tensor的计算和通信会形成一个依赖图,如图1所示:backward依赖于forward;push依赖于backward;pull依赖于push,forward依赖于pull。基于这样的依赖,深度学习框架的引擎会执行这样的一张有向无环图(DAG)。
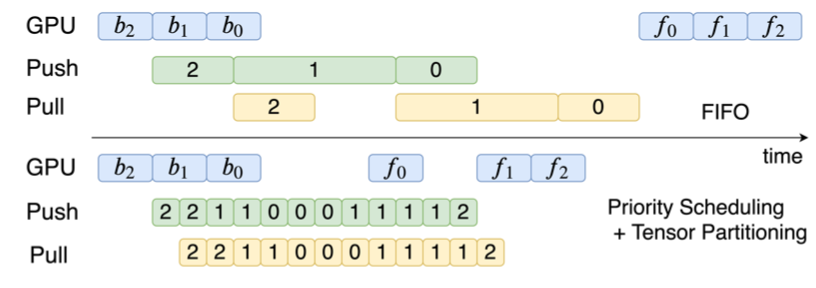
在默认的情况下,通信的操作按照“先进先出”(FIFO)的方式从模型的最后一层到第一层执行。例如,如图2所示,绿色的矩形表示push tensor,黄色的矩形表示pull tensor。从layer2到layer1,他们的计算和通信都是按照FIFO的顺序执行的。FIFO的顺序的主要问题在于它不能很好地overlap计算和通信。已有工作(例如P3和TicTac)对此的改进是通信调度,即将tensor划分成几个更小的部分并改变传输的顺序。在如图3所示的例子里,这样的方法和图2中FIFO的方法相比,训练速度提升了40%。
P3和TicTac等已有的通信调度设计都是基于特定的框架来实现的,而且他们所做的优化都是基于一些实证结果的。然而,在实际应用中,分布式DNN训练的setup是多种多样的:不仅机器学习的框架有许多种,通信的架构(all-reduce,PS)和网络协议(TCP,RDMA)也是多种多样的。因此,一种通用的通信调度方法对于整个community和工业界都是很有价值的。通用的通信调度有三点要求:(1)对于各种的setting都可用;(2)对已有框架不做大量修改;(3)实现调度上的优化。
作者观察到,无论在什么样的实验setting下,DNN训练中的计算图几乎都是一样的。几乎所有的模型都有层级结构,计算都是一层一层执行的。尽管不同的框架有不同的特性,对于同一个模型来说,不同框架运行的计算图几乎都是一样的。而且不同的通信方式也不会改变模型的计算图。基于这样的特性,作者提出了ByteScheduler:一个通用的tensor通信调度框架。ByteScheduler从不同的实验设定中抽象出tensor调度的概念,并提出了一个无论在理论上还是实际应用中都有效的调度算法。
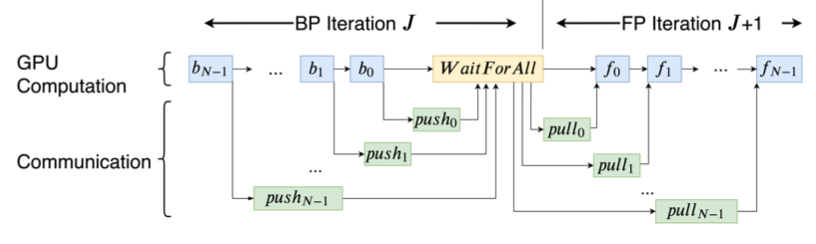
其中一个挑战是一些框架例如TensorFlow和PyTorch在两个iteration之间引入了一个barrier(图3),这个barrier的存在会使得任何对push/pull或者all-reduce的调度很低效。另一个挑战是如何适应不同的运行时环境,需要平衡训练效果和训练速度。
ByteScheduler的设计
整体架构
ByteScheduler在通信栈中位于engine层之上,API层之下。对于每一种机器学习框架,ByteScheduler都有一个把每一个通信的operation包成一个统一CommTask抽象的plugin。然后,ByteScheduler core会把CommTasks进行分割和调度。这样,ByteScheduler就可以在不同的框架之间都适用。
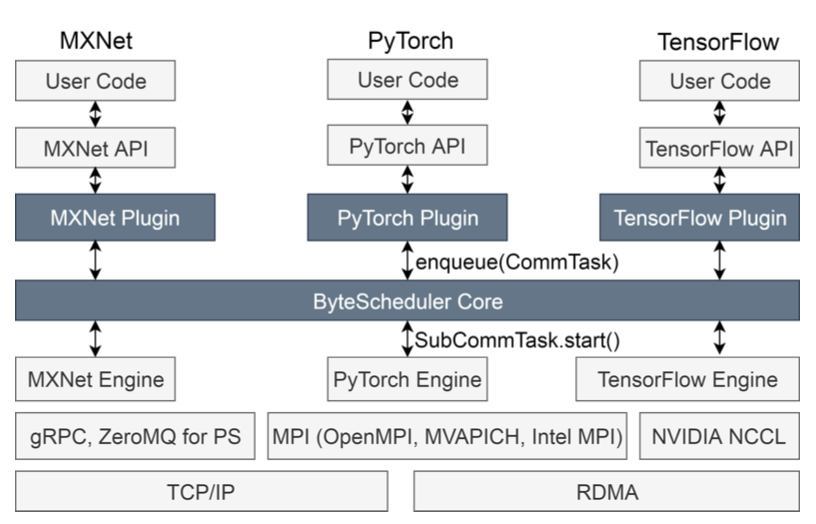
对通信任务的统一抽象
CommTask是一个通信操作的抽象,例如push一个tensor,pull一个tensor或者all-reduce一个tensor。CommTask提供了四种不同的接口,分别为:
- partition(size):划分CommTask为SubCommTasks;
- notify_ready():通知Core一个CommTask已准备就绪;
- start():开始执行一个CommTask的任务;
- notify_finish():通知Core一个CommTask已完成。
与框架Engine的交互
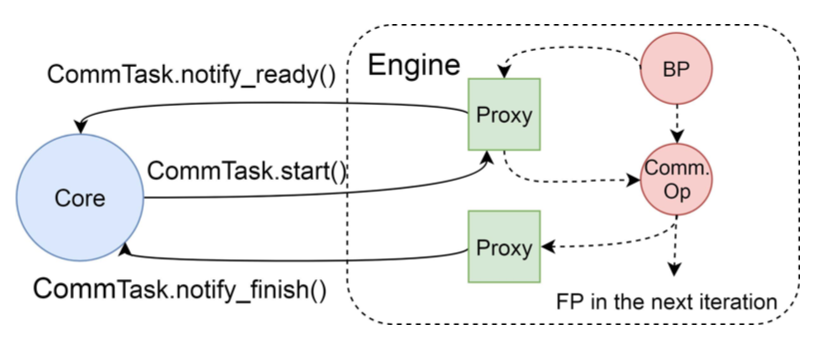
Denpendency Proxy是ByteScheduler中的一个操作(operation),它可以使ByteScheduler从框架中得到对通信调度的控制。ByteScheduler在每一个反向传播(back propagation)和通信操作之间加一个proxy,这个proxy做三件事情:(1)当一个反向传播计算结束之后,框架的engine会通过proxy通知ByteScheduler Core一个CommTask已经准备就绪,可以开始通信了。(2)当Core决定开始这个CommTask的时候,Core通过CommTask.start()来结束这个proxy(即这个proxy的生命周期是从backward结束开始、通信开始结束,它的使命就是在计算和通信之间作为控制他们执行顺序的桥梁)。(3)在CommTask结束之后,会使用另一种proxy,这个proxy只通过CommTask.notify_finish()发出信号。
而对于有barrier的机器学习框架,proxy在实现上有所不同,ByteScheduler会通过proxy来跨过barrier的限制。这个是通过“out-of-engine communication”实现的,即在engine之外进行实际的通信。ByteScheduler将原有的communication operation替换为一个异步的op,这个op会在后台开始通信。
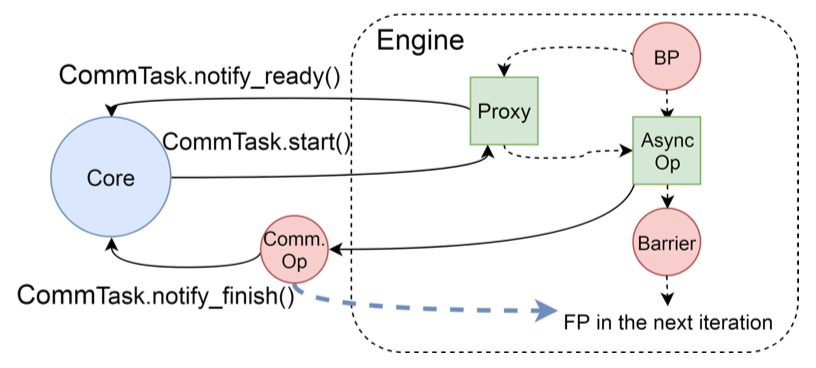
将通信改为异步通信之后,通信的op会在实际的通信执行完成之前就返回,这样可能导致下一个iteration的forward在完成通信之前就开始了计算,这违背了训练的dependency graph。为了保障每一层的计算和通信保持的正确的dependency,ByteScheduler增加了另外一种proxy,这个proxy可以block下一个iteration的forward propagation,直到通信结束。例如如图7所示,红色的线是框架原有的dependency,绿色的线是ByteScheduler的dependency。Global barrier仍然存在,但是这个global barrier不会影响通信。虽然proxy可以跨过这个barrier,但是proxy不会改变barrier所维持的通信和计算顺序的依赖。
调度算法
在通信的调度上,以前的工作采用stop-and-wait的方法,他们会在发送一个tensor之后等待通信完成,然后再发送下一个tensor。这样的方法不能充分利用网络带宽。
本文提出了Credit-based Preemption:它的工作原理和“滑动窗口”类似,credit size是窗口的大小,它允许在同一个滑动窗口内的多个tensor同时进行通信。Credit size对于这个方法来说是一个很重要的系统参数:credit size越大,可以同时通信的tensor越多,带宽的利用率就越高;但是由于通信栈是FIFO的,credit size越大,这个方法对窗口内tensor的通信顺序的调整就越不够及时。因此,找到最佳的partition size 和preemption size十分重要。
最佳的partition size 和preemption size会受到网络带宽、worker的数量、模型的结构、CPU和GPU的类型等等多种因素的影响。ByteScheduler会在运行时对最佳的参数选择进行搜索,本文使用了贝叶斯优化来自动调整参数大小。(贝叶斯优化在神经网络超参数自动化搜索中已有广泛的应用)
实验评估
ByteScheduler实现了MXNet,Pytorch和Tensorflow三种框架,用户在使用时只需要在原有框架训练代码的基础上添加两行代码就可以了。
实验使用了16台机器的集群,每台机器有8张V100。
在实验中,作者将ByteScheduler和机器学习框架本身进行比较;另外也Linear scaling(机器学习框架本身的速度乘以机器的数量)做了比较。
在对训练的加速上,对于不同的模型和不同的框架,ByteScheduler都可以极大地提升框架原有的训练效率,在一些情况下ByteScheduler的表现和Linear Scaling相似,在GPU数量较多时加速会更明显。
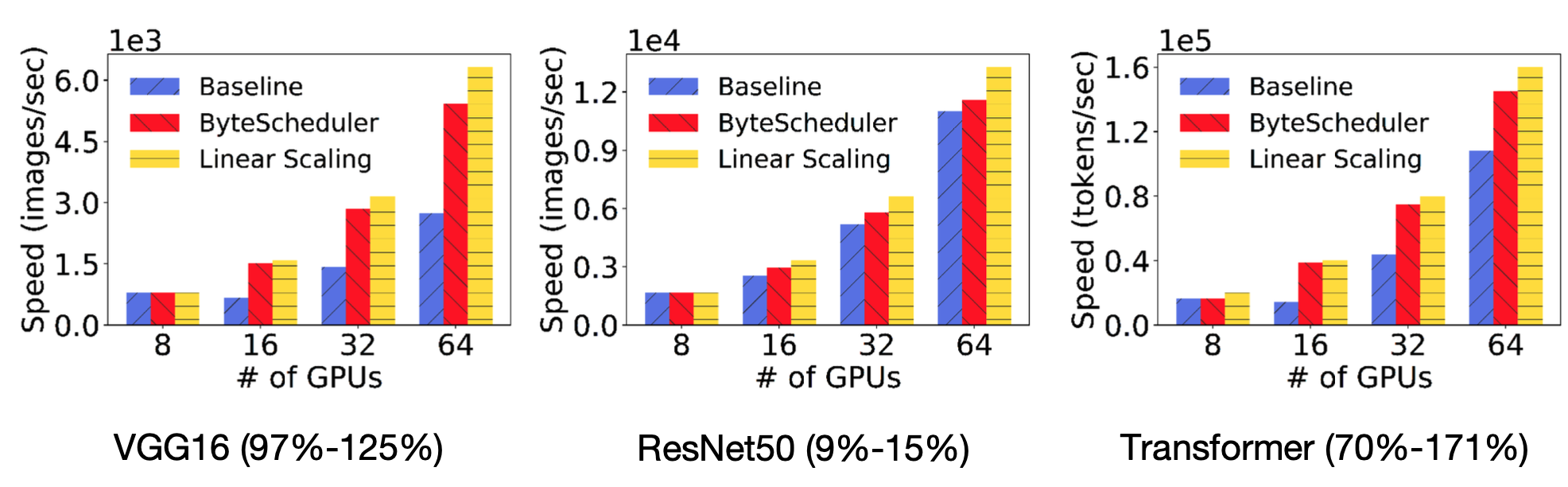
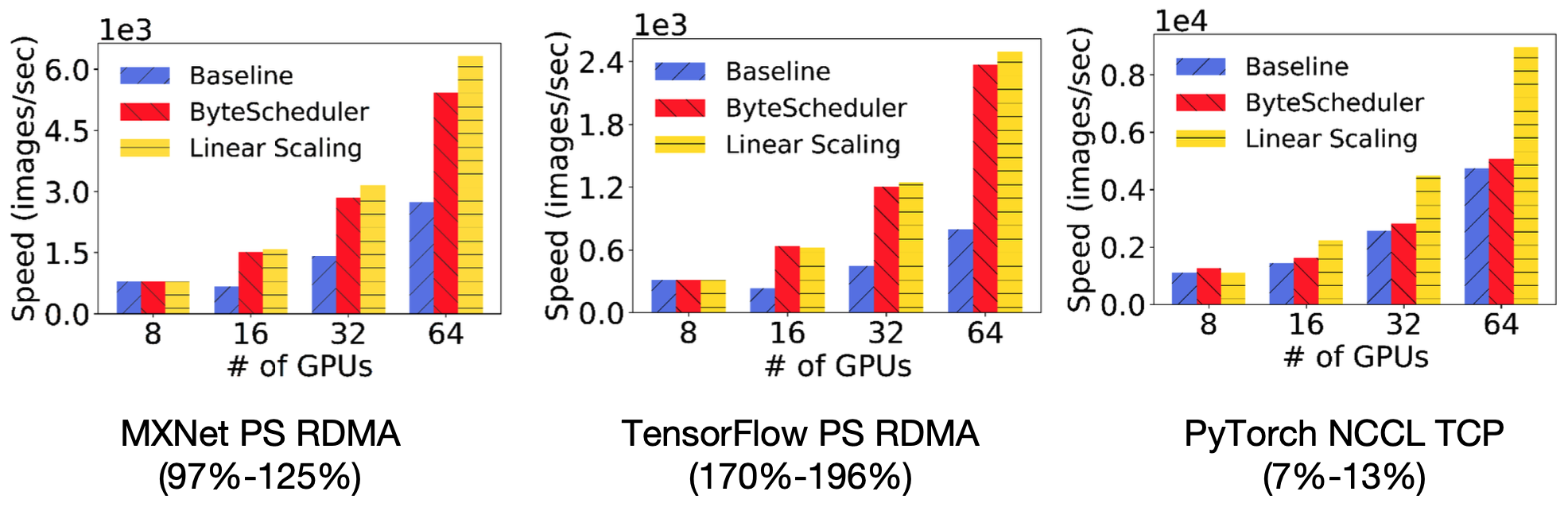
在不同的网络带宽环境下,ByteScheduler都可以提高训练速度,且对参数的自动调整对训练速度带来的提升十分明显。
总结
本文提出了一个加速分布式训练的、通用通信调度器ByteScheduler,主要有以下三点贡献:
- 提出了tensor通信调度的统一抽象;
- 在几乎没有对现有的机器学习框架的修改的情况下,实现了对多种不同框架的支持;
- 提出了可以自动调整参数的tensor调度方法。
尽管很多人表示ByteScheduler并没有论文里所带来的这么好的效果,且因为实现不够完善,用户体验不佳,但是不可否认的是ByteScheduler所提出的方法确实可以有效的解决许多问题,在工业界和学术界都很有价值,在分布式机器学习和通信调度方面有不小的影响力。
原文作者:Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo
原文链接:https://dl.acm.org/doi/pdf/10.1145/3341301.3359642