Machine Learning at Facebook: Understanding Inference at the Edge
- Android设备上,AI边缘计算硬件碎片化严重。排名前50名的SoCs也仅仅占整个Android市场的65%,只有排名前225的SoCs才能占到95%的Android设备。
- 移动端CPUs多样化且非常旧,大约有一半的CPU都具有两个CPU集群(高性能核心集群与节能核心集群)。
- 移动端就算使用GPU进行AI边缘计算,但整体情况也不容乐观:大约只有11%的设备中GPU的推理速度是CPU的3倍,只有23%的设备GPU的推理速度是CPU的2倍,绝大部分的设备使用GPU推理速度提升并不明显,甚至还有下降。
- 移动SoCs的产品策略问题:中端SoC的CPU一般只比高端SoC慢10% - 20%,但是GPU却慢了2至4倍;
- 不同于PC,移动端SoC中CPU与GPU共用内存,两者之前会争夺稀缺的内存带宽。
- 运行在高通SoC上的Facebook程序,只有5%的设备具有“计算”DSP,市场中大多数的DSP没有集成“计算/矢量”DSP;
- 可编程性是GPU与移动协处理器运用的主要障碍:OpenCL库与驱动的不稳定性,导致不能大规模使用。
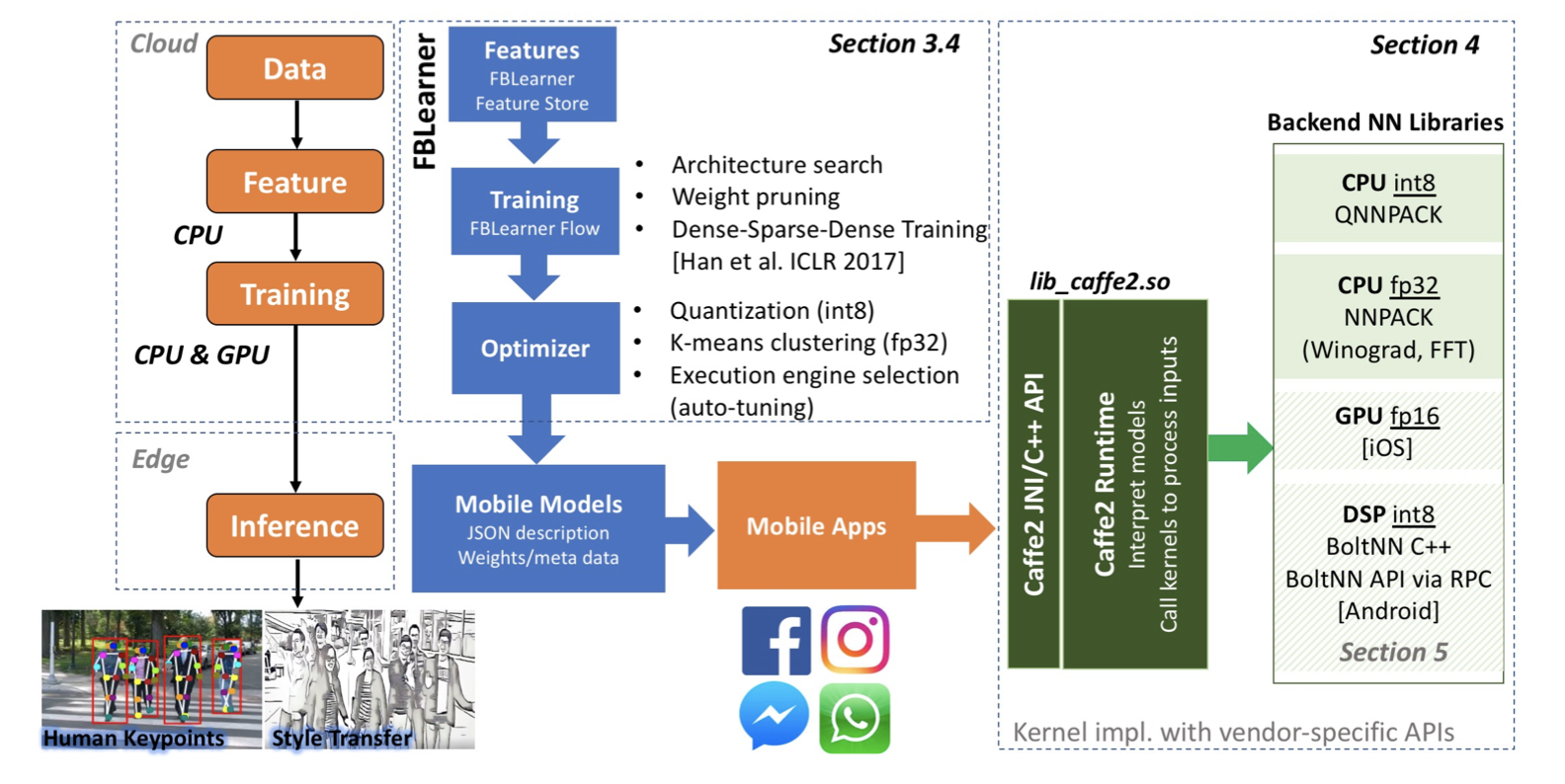
图1:Facebook移动端机器学习的执行流程
原文作者:Carole-Jean Wu, David Brooks, Kevin Chen, Douglas Chen, Sy Choudhury, Marat Dukhan, Kim Hazelwood, Eldad Isaac, Yangqing Jia, Bill Jia, Tommer Leyvand, Hao Lu, Yang Lu, Lin Qiao, Brandon Reagen, Joe Spisak, Fei Sun, Andrew Tulloch, Peter Vajda, Xiaodong Wang, Yanghan Wang, Bram Wasti, Yiming Wu, Ran Xian, Sungjoo Yoo, Peizhao Zhang
原文链接:https://research.fb.com/wp-content/uploads/2018/12/Machine-Learning-at-Facebook-Understanding-Inference-at-the-Edge-v2.pdf