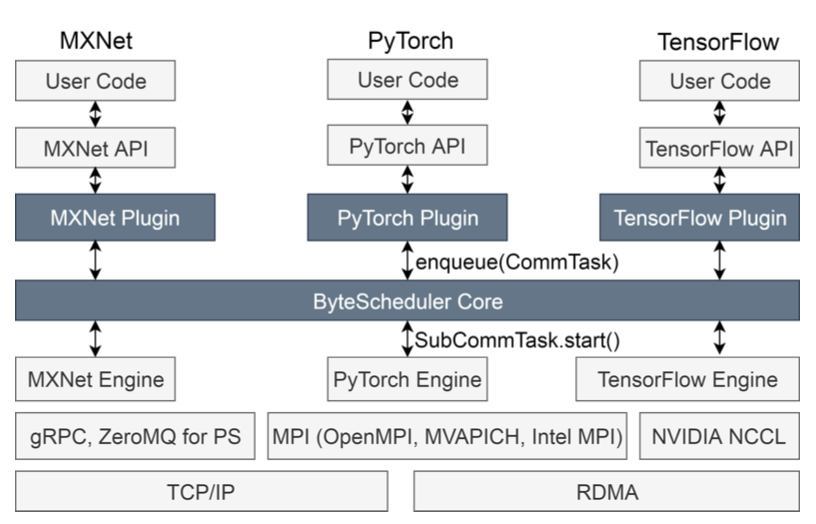
Lineage Stash: Fault Tolerance Off the Critical Path
目前主流的分布式计算框架通过全局快照和日志这两种方式之一来实现容错。全局快照的运行时开销小,因为是异步的,但是恢复很慢,因为需要把上一个快照之后的操作回滚再重来。使用日志的话,因为粒度比较细,所以恢复的时候比较快,只要跟着日志走就行了,然而平时的计算都需要等日志写完才能进行,也就是在关键路径上,所以运行时的开销很大。这篇文章提出了 lineage stash 的方法,能够减少日志方法的运行时开销,但又能实现高效的恢复。
大体上他们的方法是在把任务交给另一个节点处理的时候,顺便带上当前节点的日志,同时异步地把日志写到一个全局的存储上面。这样一来,如果有一个节点挂了,其他节点可以把这个节点的日志写到全局存储上面,这样这个节点重新上线开始恢复的时候就可以完整地得到之前自己的日志,而且在平时执行任务的时候也不用等到日志写到存储上面。
背景知识
Stage:以shuffle为界,当在一个job任务中涉及shuffle操作时,会进行stage划分,产生一个或多个stage。partition个数即rdd的分区数,不同的数据源读进来的数据分区数默认不同,可以通过repartition进行重分区操作。
目前常见框架应用的两种容错机制:
- global checkpointing,是基于logging的方法。该方法在运行时必须不断记录,造成运行时开销大。但是这样的记录可以减少recovery时replay的开销。
- 基于lineage的方法,记录每一个stage的lineage(计算图)。出现failure时数据重构的消耗很大,但是在运行时开销小。
本文提出的Lineage Stash方法:一个在运行时和恢复时开销都很小的causal logging方法,可用于细粒度data processing应用。
Challenge
- 目前记录lineage以batch为粒度,而传统的lineage-based方法以partition为粒度(包含多个batches),现在记录的力度小,记录量大,严重影响了延迟和吞吐量(为什么要设计一个更细粒度的记录呢??)
- lineage一定要在运行时更新,以保证后续恢复和之前的记录处理相同
- 设计刷新和恢复lineage的简单、稳定的方案
Overview
Lineage stash保证,如果一个处理过程fail了,从上一个checkpoint起,它收到的任何消息(message)会被以同样的顺序replayed。
lineage stash采用casual logging的方法做record和relay计算。casual logging会异步地向一个稳定的存储系统里不断地记录“不确定的事件”,在发生failure时,因为所有的“不确定事件”都被记录了并可以replay,所以这保证了global consistency。casual logging在实际应用中会遇到困难:不确定的事件种类繁多,且记录一定要全,这导致任务繁重且开销过大。好在通常data processing的应用中主要都是纯计算。主要的问题在于在data processing application中如何鉴别出并捕捉不确定性的源头。有三个要回答的问题:记录什么信息、如何记录信息、如何从这些记录中恢复。
记录什么信息
减少不必要的记录,例如无需重复记录相同的执行顺序;无需记录完全不确定的执行顺序等。
对于完全确定性的计算,可以记录计算图(lineage)而非原始数据。特别地,我们记录一个指向应用数据的指针(object)和对计算的简单描述(task)。一个object的数据图包括产生这个object的task,以及这个task的每一个参数的数据图。
对于不确定性的计算,就有必要记录计算顺序了。具体情况具体分析,记录的信息随机应变。
如何记录信息
传统方法:在task执行之前记录计算图的依赖关系
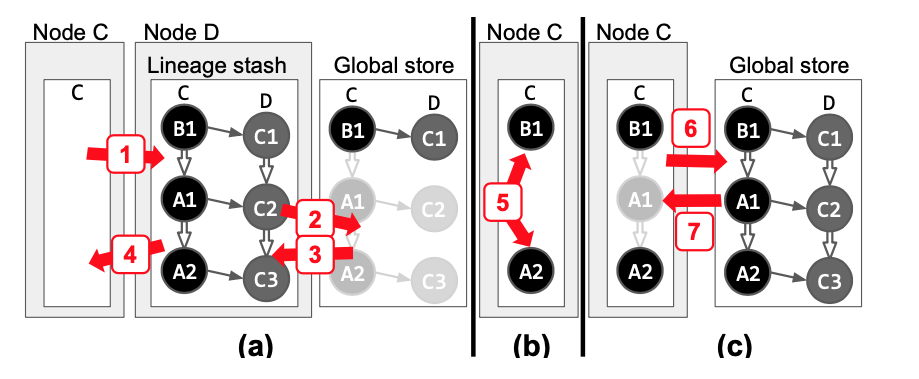
Lineage stash的方法:向下面的节点传递task输入数据的计算图。这样,执行任务的节点有所有重构输入的信息。
确定性的计算图的执行顺序无需被传递,因其确定性,这些计算图可以被准确无误地重建。每一个进程只需要记录它曾传递过的task。如果一个进程fail了,向这个进程传递过task的进程将重新传递tasks以帮助恢复进程状态。
不确定性的应用中,除了task以外,进程还需要向前传递它所见过的所有的计算图,因为task描述随着执行过程的进行会改变,仅仅传递task描述是不足够的。除了local stash以外,还有一个global linage storage。
如何从记录中恢复
提取并重新执行计算图。
For each process p and task T that p has executed or submitted, T ’s lineage is in p’s local stash.
For each process p and task T that p has executed or submitted, T ’s uncommitted lineage is in p’s local stash.
Latency:和WriteFirst方法相比较,对于确定性的计算图,Lineage stash的方法latency更小;对于不确定的计算图,lineage stash的方法latency更大,如果限制该方法中lineage可向前传递的次数,latency变得稳定。
应用:在分布式训练,数据流处理等方面都有具有优势(发生Failure时恢复得更快)。
原文作者:Stephanie Wang, John Liagouris, Robert Nishihara, Philipp Moritz, Ujval Misra, Alexey Tumanov, Ion Stoica
原文链接:https://dl.acm.org/doi/pdf/10.1145/3341301.3359653
参考文献:[1] SOSP 2019 有哪些值得关注的论文? https://www.zhihu.com/question/336446443/answer/872624113