
网络是分布式训练的瓶颈吗?
在这篇文章中,作者度量并分析了分布式训练的网络表现。作者预期,度量结果会证实通信是阻碍分布式训练达到linear scale-out效果的原因。但是,作者发现实际上网络带宽利用率很低,如果网络带宽可以被充分利用,分布式训练的scaling factor可以接近于1。
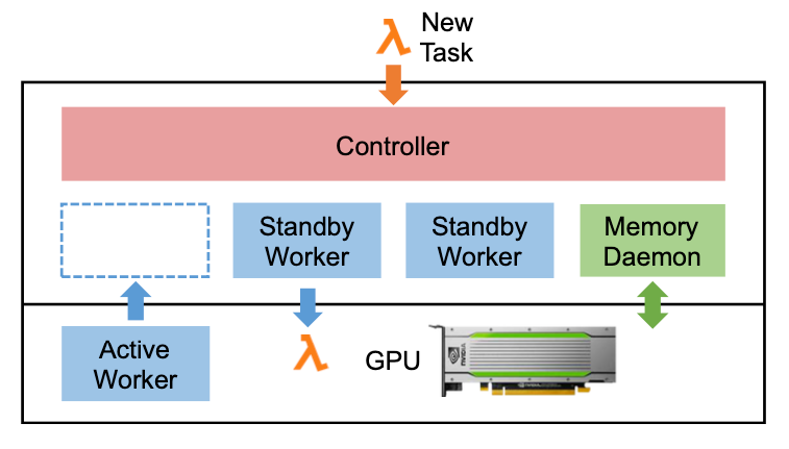
PipeSwitch:面向深度学习应用的高效多进程管理
本文提出了一个PipeSwitch系统,它可以使一个推理程序的未使用周期由训练或其他推理应用程序填充。它允许多个DL应用程序与整个GPU内存共享同一个GPU,并只增加毫秒级的切换开销。使用PipeSwitch,GPU利用率可以显著提高,且不会牺牲SLO。本文还设计了统一的内存管理和Active-Standby Worker切换机制,以配合上下文切换的流水线并确保进程间的隔离。
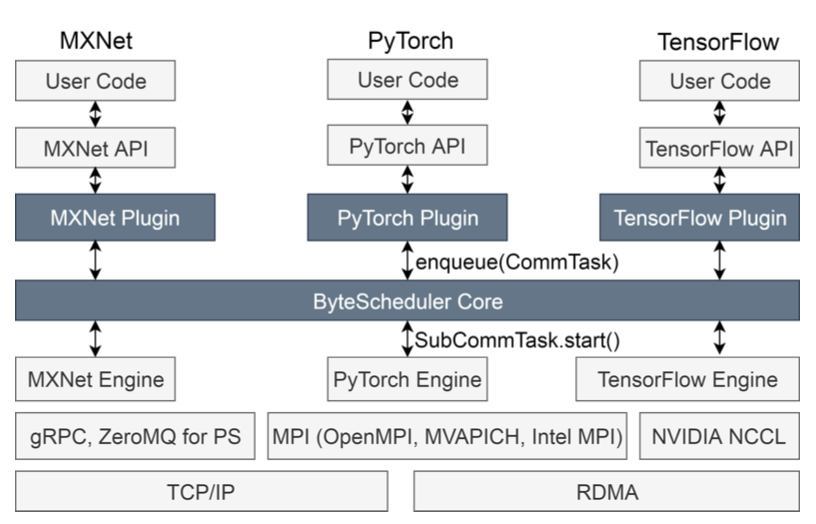
ByteScheduler: 加速分布式训练的通信调度器
本文提出了一个加速分布式训练的、通用通信调度器ByteScheduler。它引入了一个统一的抽象和一个依赖代理机制来实现通信调度,且不破坏框架引擎中原有的依赖关系。在此基础上,本文提出了一种贝叶斯优化方法,可以在不同的网络环境下,根据不同的训练模型自动调整tensor划分的大小和其他参数。ByteScheduler现在支持TensorFlow、Pythorch和MXNet,无需修改它们的源代码就可以很好地与参数服务器(PS)和all-reduce架构(使用TCP或RDMA)进行梯度同步。

AntMan:面向深度学习的GPU集群动态弹性伸缩方法
本文介绍了一个面向深度学习的、可以实现集群资源弹性伸缩的系统AntMan,它与深度学习框架共同设计集群调度程序,并已在阿里巴巴中部署,用于管理数千个GPU上的数万个日常深度学习作业。AntMan利用深度学习训练的独特特性,在深度学习框架中引入了内存和计算的动态缩放机制。
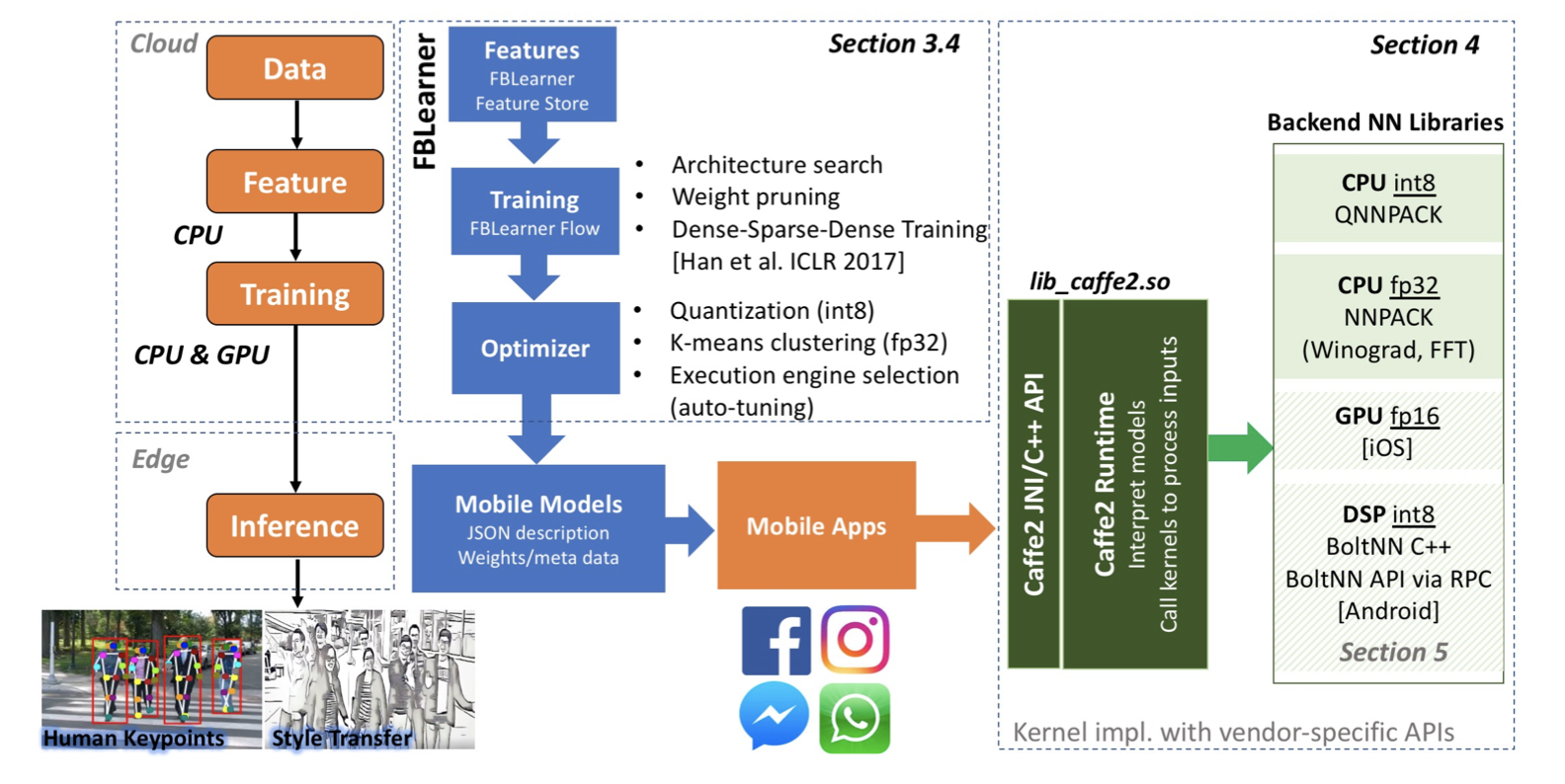
Facebook在边缘设备上的ML推理计算的现状
本文介绍了Facebook机器学习在边缘设备上进行推理的现状。
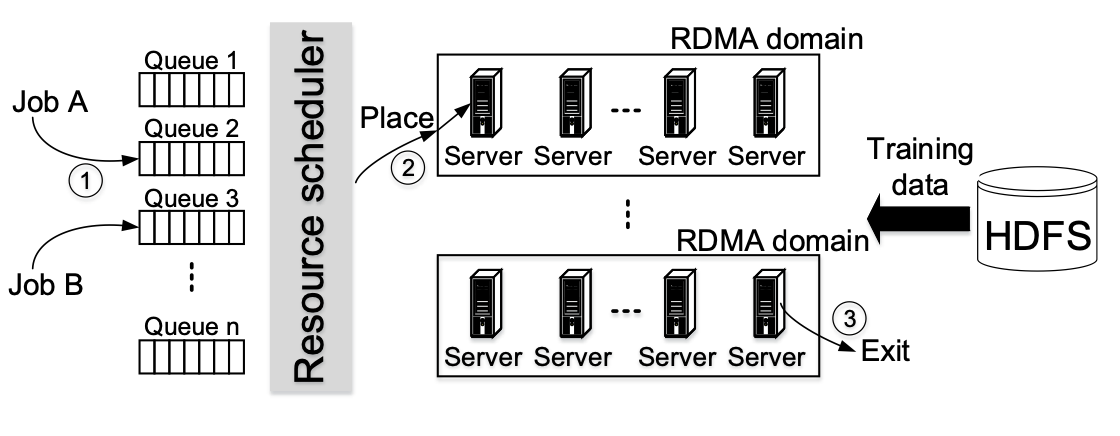
分析面向DNN训练的大型多租户GPU集群
本文分析了微软Philly上的trace,并为下一代的GPU集群调度器提出指导性建议。
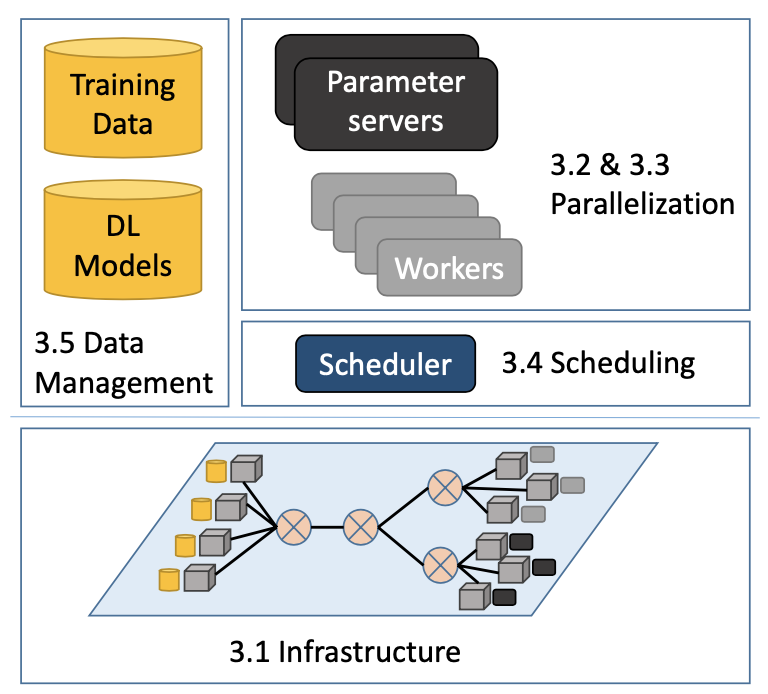
分布式设施上的可扩展深度学习:挑战、技术、和工具
本文探索了分布式设备中深度学习的“可扩展性”的挑战、方法和工具,包括用于深度学习的设备、并行深度学习训练的方法、多租户资源调度、训练和模型数据管理四个方面。
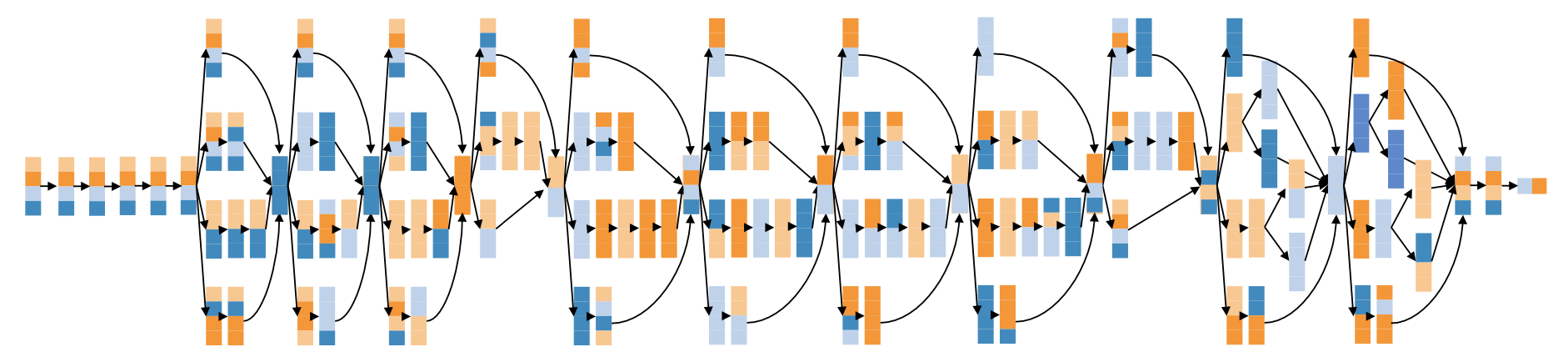
更多维度的深度神经网络并行策略
FlexFlow用了一个创新性的、可以准确预测一个并行策略的表现、比原有方法更快速的执行模拟器。
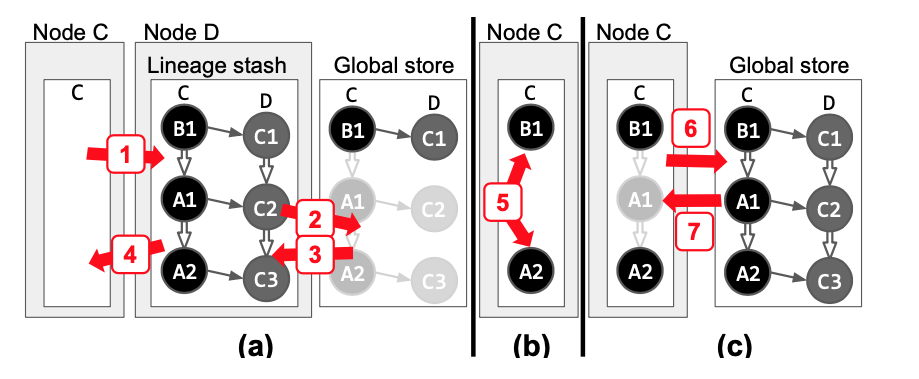
Lineage Stash:在关键路径之外的容错机制
集群计算框架在计算时如果发生Failure,如何恢复到发生failure之前一模一样的状态?




